How Kimi K2 RL'ed Qualitative Data to Write Better
Our last post on Kimi K2 dives into how the Moonshot team used reinforcement learning (RL) on qualitative tasks. If you haven’t already, check out the last two explorations:
- How Rewriting Training Data Improved Kimi K2’s Performance
- How Kimi K2 Became One of the Best Tool-Using Models
Kimi K2 has already been overshadowed by several other open models (everyone’s pushing it all out the door ahead of August 2nd, when the EU AI Act goes into effect), but it continues to impress when it comes to writing. Let’s take a look at how Moonshot achieved this feat.
RL’s Verifiable Boundary
In our synthetic data explainer, we wrote:
Spend some time reading technical papers for new models and you’ll notice a theme: a good chunk of the content deals with quantitative problems. Math and code are the focus right now, with new and complex synthetic data pipelines refashioning seed data and testing the results. The headline evaluations are quantitative tests, like MATH and HumanEval. Synthetic data is pushing models further and delivering improvements, especially in areas where synthetic data can be generated and tested.
If you can test the synthetic data you create with unit tests or against factual answers, the sky’s the limit. However, with qualitative or non-verifiable tasks, there’s no cheap or easy way to score the work:
There are additional sources of data that can help mitigate this bias. Proprietary user-generated data – like your interactions with Claude or ChatGPT – provide human signal and qualitative rankings. Hired AI trainers will continue to generate feedback that will tune and guide future models, but all of this relies on humans, which are slower, more expensive, and more inconsistent than synthetic data generation methods.
As a result, LLMs have advanced incredibly over the last year in math and coding tasks. But their qualitative improvements have lagged behind. From our reasoning model explainer:
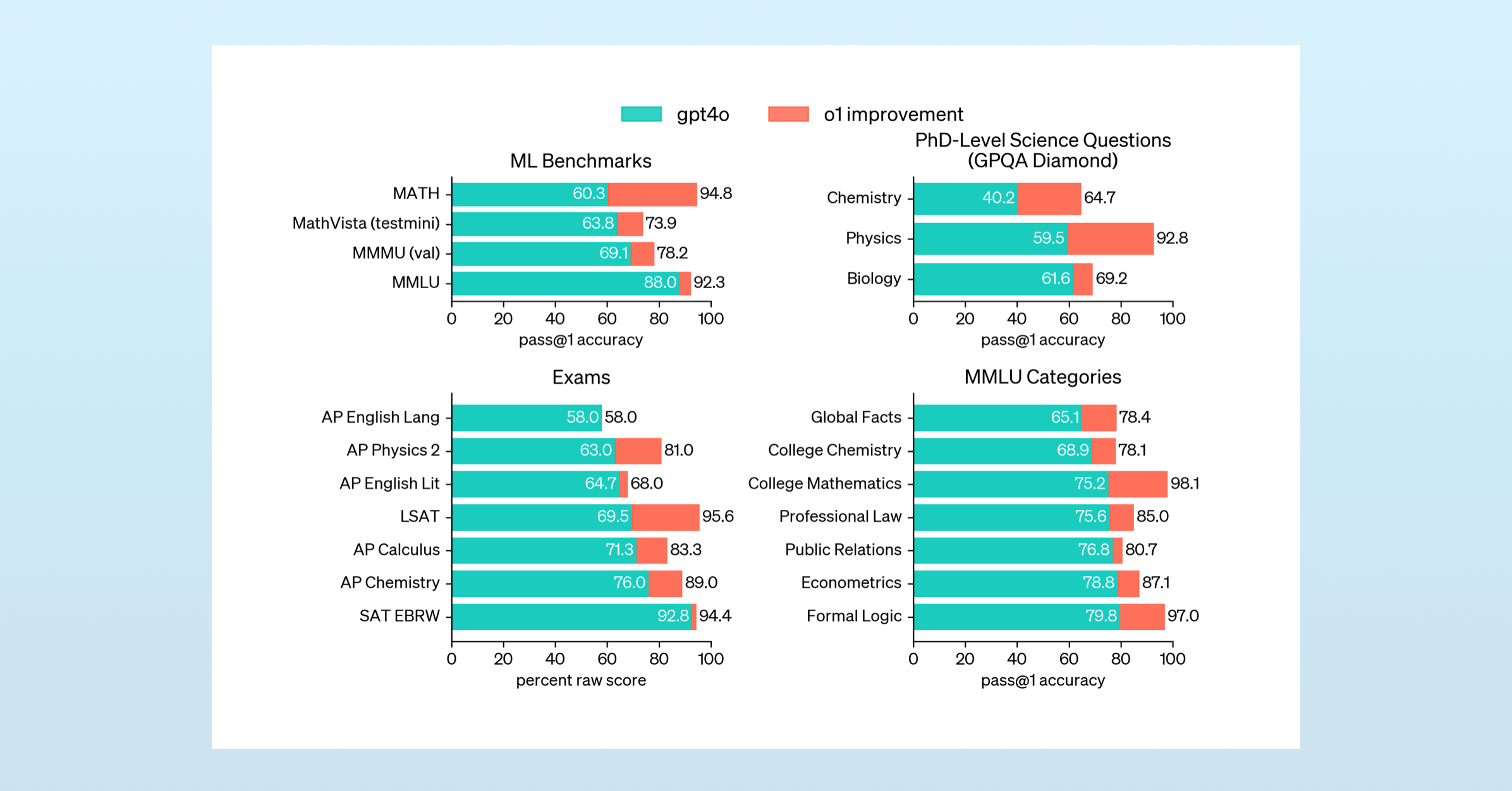
Reasoning models deliver outsized performance in quantitative fields, like math and coding, but only slightly move the needle in qualitative domains.
This limitation was immediately apparent with o1, whose English Literature and English Language scores closely matched non-reasoning models.
Many teams have tried or are trying to use LLMs to evaluate qualitative performance, but most of these attempts have been spoiled by reward hacking:
During reinforcement learning, the model being trained often finds unexpected ways to maximize its score without achieving the intended goal. This is “reward hacking,” and it’s the bane of RL engineers.
DeepSeek R1’s technical paper cites reward hacking as the reason LLM evaluation wasn’t used at any stage of its post-training.
This boundary – our current inability to generate high-quality qualitative synthetic data and use it for post-training, at scale – is one of the areas I’ve been watching. If we were able to improve LLM writing and qualitative discernment at the rate we’ve achieved for math and science, I expect we’d see a dramatic increase in the practical applications of LLM.
The Underappreciated, Imperfect Rubric
In 2012, the statistician and the father of sabermetrics, Bill James, took a break from sports analytics to write a book about American true crime, Popular Crime. The book is free-ranging and indulgent, yet continually interesting. Popular Crime is enjoyable because you can see James trying to make sense of the ocean of true crime books he’s read in a structured manner, similar to the way his metrics revolutionized baseball.
But true crime stories aren’t measured the same way baseball is. There aren’t batting averages, slugging percentages, or fielding rates for serial killers. Finally, in chapter 10, he breaks into a digression, explicitly stating his problem:
Suppose that we were to categorize crime stories. Let us pretend that you and I are academics who wish to study crime stories, and, as a first step in that process, we need to sort them into categories so that we can study groups of like stories. How would we do that? …It turns out to be too complicated to categorize stories in that way, as crime stories contain different mixes of elements.
For several pages he chews on the possibilities, testing it with random cases, before settling on 18 elements that can be used to categorize crime stories. The initials of each category, paired with a 1-10 score for “the degree of public interest”, can then be used to annotate stories. For example:
- “The trial of Clarence Darrow, then, might be categorized as CJP 9 – a celebrity story involving the justice system, with political significance, very big.”
- “The story of Erich Muenter would be PB 7 – a poltical story with a somewhat bizarre twist, attracting strong short-term national interest.”
- “The murder of Stanford White by Harry K. Thaw was CT 9 – a Celebrity/Tabloid story, very big.”
This system – which rarely is used throughout the remainder of the book (though often enough you know he coded everything for his own reference) – always struck me as a very useful analytical technique.
As an engineer, data scientist, analyst, or researchers you will constantly encounter things you want to understand which are not easily measurable. When faced with this scenario, most will choose an alternate, proxy metric that doesn’t really measure what they want to understand. But it exists, and that’s sufficient, allowing the analyst to push forward towards their ultimate goal. Occasionally, the analyst will get distracted and attempt to build a mechanism for precisely measuring their target phenomenon. (In AI today, this manifests itself as the creation of a new benchmark!)
James’s crime story rubric illustrates something crucial: when dealing with complex, qualitative phenomena, imperfect categorization often beats the alternatives. Rather than abandoning systematic analysis entirely or waiting for a perfect measurement system that may never come, breaking down the complexity into manageable, assessable components lets you make progress.
This principle directly applies to the challenge facing AI researchers today. When training models on qualitative tasks like writing, you’re essentially trying to optimize for something as multifaceted as James’s crime stories. “Good writing” contains different mixes of elements—clarity, engagement, tone, accuracy, style—that resist simple scoring. Most teams either give up on systematic improvement here (focusing instead on quantitative tasks where progress is measurable) or create overly simplistic proxies that miss the mark entirely.
But there’s a third path: accept that your categorization will be incomplete and imperfect, but recognize that systematic incompleteness is still superior to systematic neglect. You don’t need to capture every nuance of good writing—you just need categories that are consistent enough to guide improvement and specific enough to resist gaming.
This is exactly the approach Moonshot took with Kimi K2, and their method demonstrates how productive rough categorizations can be when applied thoughtfully to RL for qualitative tasks.
Here’s what they did:
- Establish an Initial Baseline: Moonshot used Kimi K2 to score itself here, so it needed a baseline of preferences to act as a competent judge. Moonshot assembled, “a mixture of open-source and in-house preference datasets,” which initialized its critical ability during the fine-tuning stage.
- Prompt the Model & Score it Against a Predefined Rubric: Moonshot then generated responses from Kimi K2 with a wide range of prompts. Another instance of Kimi K2 then scored pairs of responses against three rubrics, which are:
- Core Rubric: The main behaviors they wanted to optimize for.
- Clarity and Relevance: “Assesses the extent to which the response is succinct while fully addressing the user’s intent. The focus is on eliminating unnecessary detail, staying aligned with the central query, and using efficient formats such as brief paragraphs or compact lists.”
- Conversational Fluency and Engagement: “Evaluates the response’s contribution to a natural, flowing dialogue that extends beyond simple question-answering. This includes maintaining coherence, showing appropriate engagement with the topic, offering relevant observations or insights, potentially guiding the conversation constructively when appropriate…”
- Objective and Grounded Interaction: “Assesses the response’s ability to maintain an objective and grounded tone, focusing squarely on the substance of the user’s request. It evaluates the avoidance of both metacommentary (analyzing the query’s structure, topic combination, perceived oddity, or the nature of the interaction itself) and unwarranted flattery or excessive praise directed at the user or their input.”
- Prescriptive Rubric: Defensive metrics to prevent reward hacking.
- Initial Praise: “Responses must not begin with compliments directed at the user or the question (e.g., “That’s a beautiful question”, “Good question!”).”
- Explicit Justification: “[Avoid] Any sentence or clause that explains why the response is good or how it successfully fulfilled the user’s request. This is different from simply describing the content.”
- And a human-annotated rubric for specific contexts, which Moonshot did not share.
- Core Rubric: The main behaviors they wanted to optimize for.
- The Model is Continuously Updated, Improving the Critic: While the above is happening, Kimi K2 is continually being refined from this scoring and verifiable training, allowing it to apply learning from objective signals to the squishier assessments above.
The design of the rubrics echos James approach to organizing popular crime: clear categories and assessments can be easily sorted and compared. Neither approach pretends to be perfect or comprehensive. But this sorting is more consistent and productive than nothing. And by keeping these few rules tightly defined and non-comprehensive, there’s less room for reward hacking to occur.
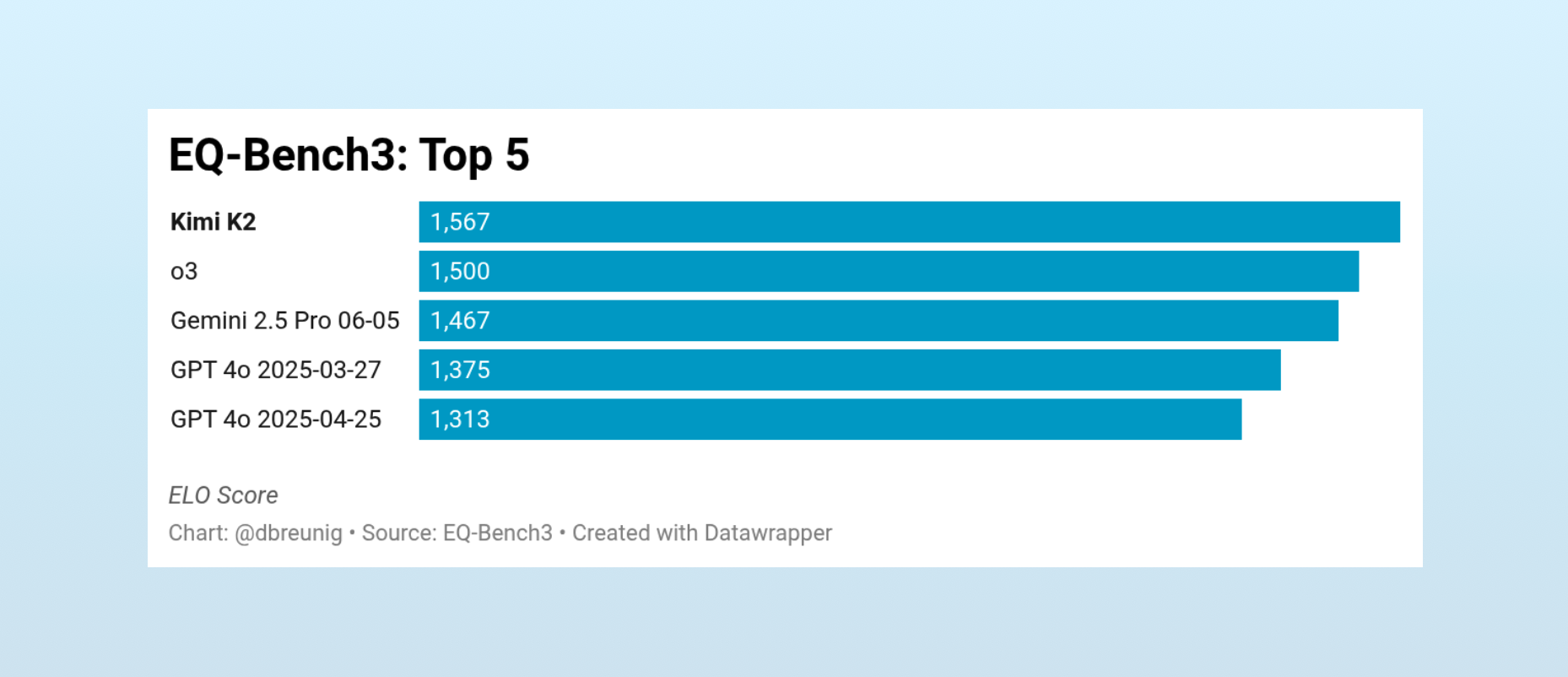
As of last night, Kimi’s sat at the top of EQ-Bench, an “emotional intelligence benchmark for LLMs.”
…Though, the AI ecosystem doesn’t sleep. Since writing this, a new model has claimed the top spot: a ‘cloaked’ model named Horizon Alpha. Given the slop forensics for Horizon Alpha, I’m wagering that’s OpenAI’s much anticipated open-weight model – which would preserve Kimi K2’s prestigious company. And still: Kimi-K2 retails the top spot on the creative writing leaderboard.
As far as areas for improvement, Moonshot acknowledges that the rules above encourages Kimi K2 to be, “confident and assertive, even in contexts involving ambiguity or subjectivity.” This results from the avoidance of self-qualification and a preference for clarity and focus.
Kimi K2’s performance demonstrates that a rough, rubric approach is better than nothing and limits the reward hacking seen with other qualitative, LLM-evaluated, RL approaches. By accepting imperfect but systematic categorization over perfect but impossible measurement, Moonshot shipped a model that excels at qualitative tasks—an area where most teams struggle to make meaningful progress. The approach isn’t without trade-offs, but it offers a practical path forward for all model builders when dealing with non-verifiable skills.