Using 'Slop Forensics' to Determine Model Ancestry
Yesterday, after playing with some smaller models, I started to experiment with the idea of a flowchart for determining a model’s ancestry with a few prompts. For example, could you ask it about state-censored topics and about its development and figure out what model was it trained by or from. Luckily I aborted that effort, because Sam Paech, who maintains EQ-Bench, has built an entire “slop forensics” pipeline.
According to Sam, his tool “generats a ‘slop profile’ for each model…then use[s] a bioinformatics tool to infer lineage trees, based on the similarity of the slop profiles.” In a nutshell, by generating and analyzing creative writing output from each model, fingerprints based on the frequent and/or unique phrases used can be constructed and compared.
You can view these profiles by visiting EQ-Bench and clicking the “i” next to the “slop” score. Here’s what the new DeekSeek R1’s profile looks like:
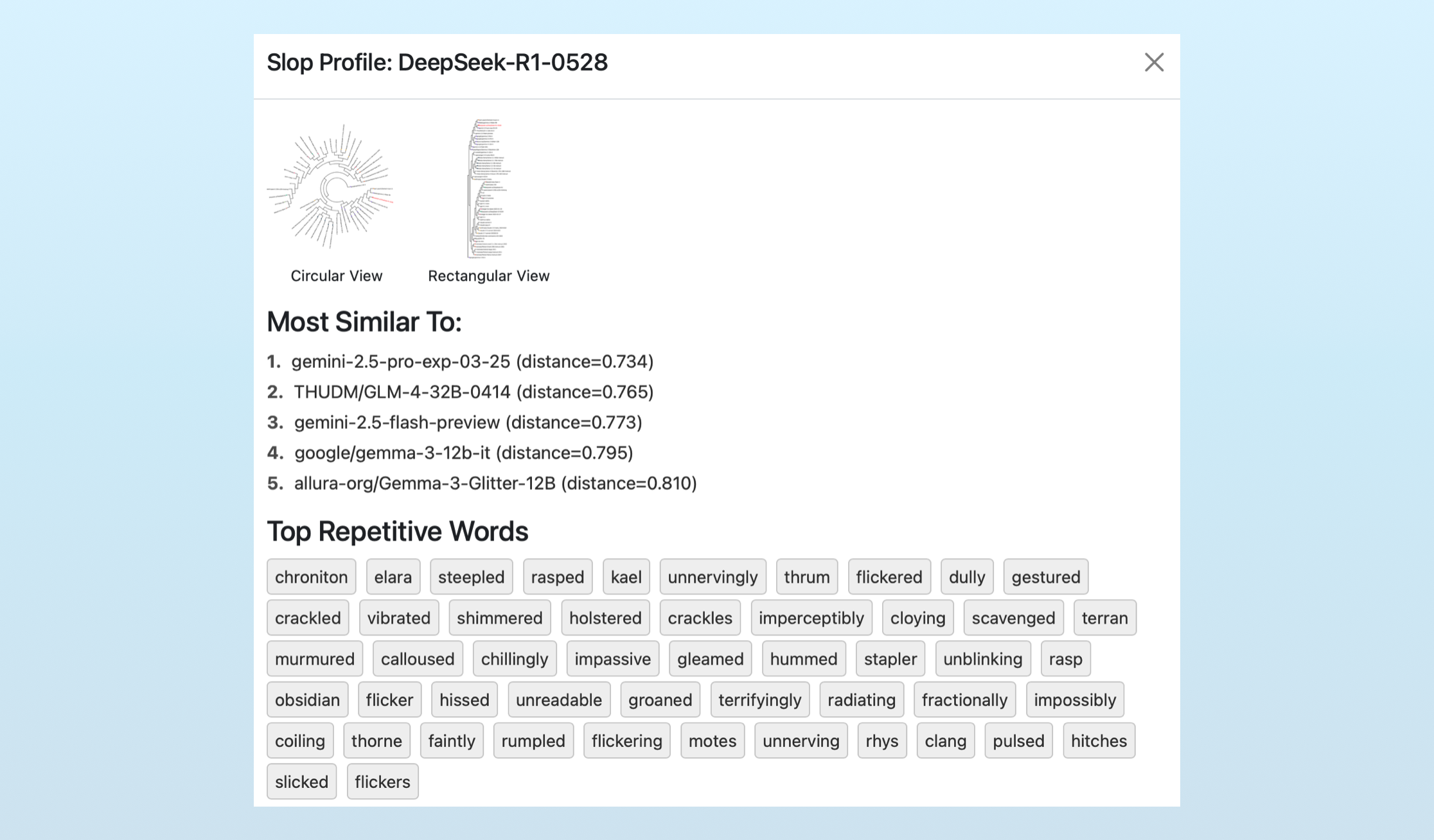
Interestingly, Sam’s slop forensics reveal DeepSeek has likely switched from OpenAI’s models to Google’s Gemini models for generating their synthetic data. As a result, DeekSeek now sounds more like the Google family of LLMs. A visualization produced by his tool shows the dramatic switch:
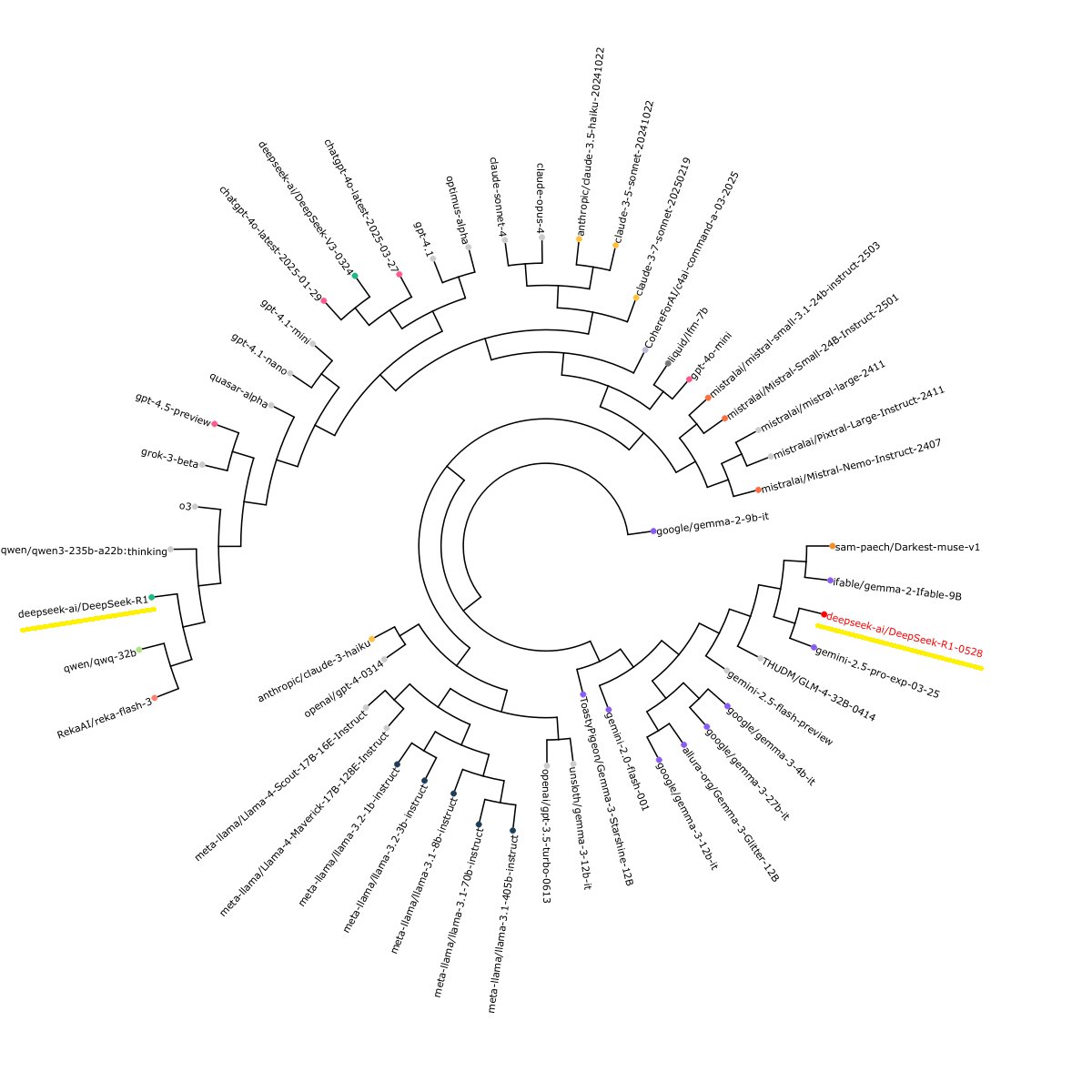
The tool also highlights how these models are converging, with each using (previously) unique names like, “Elara,” when writing fantasy fiction. This is an understudyed impact of our current reliance on synthetic data, especially for non-verifiable fields like creative writing.
If we’re sharing datasets or using the same models to generate new datasets, conversion is likely to occur. Which isn’t ideal, if we want for creativity and diversity in our LLMs.