How Rewriting Training Data Improved Kimi K2's Performance
Two weeks ago, Beijing-based Moonshot AI launched Kimi K2, an open source model that rivaled the coding capabilities of larger, closed models. It’s a really impressive model (though it’s coding capabilities have since been overshadowed by Qwen 3 Coder), especially since it’s cheaper to run than Claude 3.5 Haiku.
But there’s three topics in Moonshot’s technical paper that I want to touch on. Today, let’s look at how Moonshot AI rephrased its training data to increase its size, without overfitting. (Later we’ll look at how they optimized for agentic tool use and look at how they used RL on qualitative data.)
Rephrasing Content to Save on Training
In a nutshell, LLMs are built in two distinct phases:
- Pre-Training: Pre-training builds the foundation of the LLM. The model’s weights are built by processing mountains of unruly text data – compiled from the internet, books, transcriptions, etc. – essentially learning to predict what word or token comes next in a sequence. This process gives the model its fundamental language understanding, grammar, and knowledge base. However, after pre-training, the model is rough around the edges. It can’t answer questions or perform tasks, it just guesses the next token.
- Post-Training: Post-training tunes the pre-trained model for the desired use case. Smaller, curated datasets teach the model how to follow instructions, respond to questions, and refuse harmful requests. After post-training, a ‘chat’ model can respond to your questions in a natural manner, while leveraging everything it learned during pre-training.
We’ve previously written about how researchers tried to combine the two steps by rephrasing the original text data into a form that matches the desired behaviors learning during post-training. They took their pre-training data and adjusted it like so:
The idea was that you’d need less training to produce a high-quality model, if the input data came pre-formatted. A team from Apple and CMU found they could train a similar model 3x faster.
But the method wasn’t perfect. The team at Microsoft that built Phi-4 used a similar rephrasing technique to train their model to reason, but found that without a “base” of non-rephrased data the model wasn’t good at understanding unruly user input. Further, this technique yielded benefits for smaller models, mostly.
Rephrasing Content to Prevent Overfitting
The Moonshot AI team, however, took a novel approach to rephrasing. Rather than using rephrasing to skip post-training work by rewriting text in a chat or chain-of-thought format, Moonshot AI restated information in “varied styles and perspectives.”
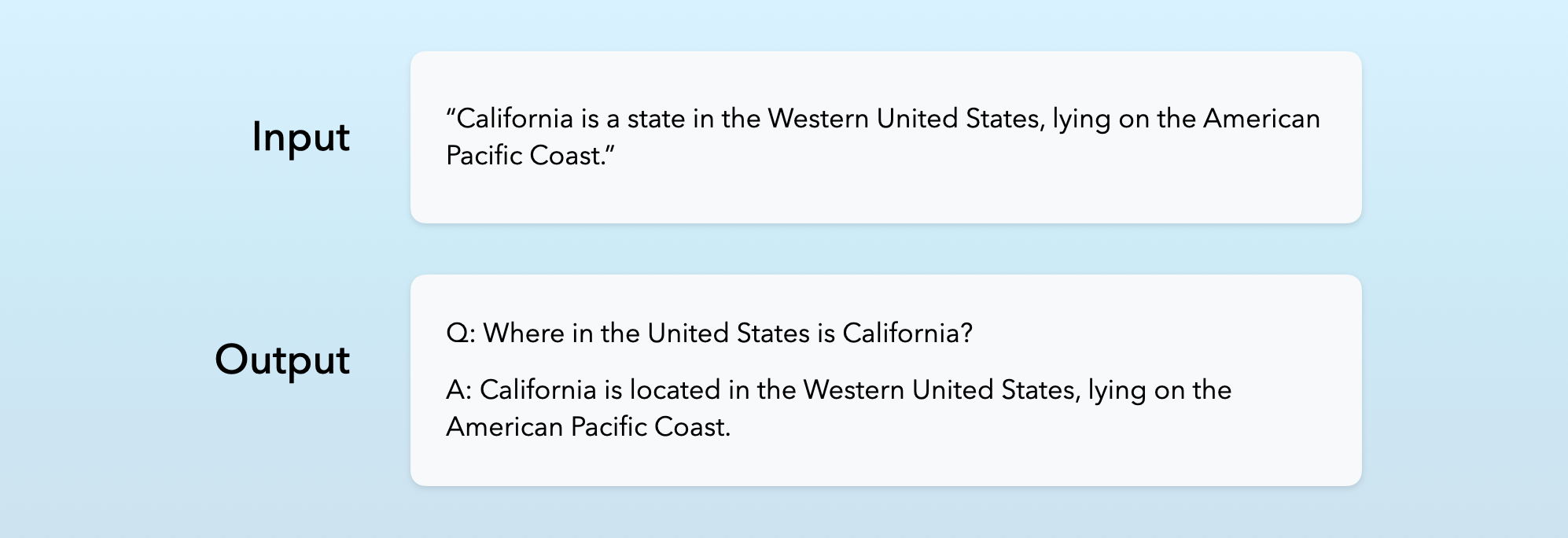
So if we had a sentence in our training data that read, “The new restaurant serves authentic Italian cuisine made with imported ingredients,” we might generate:
- A foodie rewrite: “This culinary gem transports diners straight to Italy, crafting traditional dishes with genuine ingredients sourced directly from the Mediterranean.”
- A business rewrite: “The establishment differentiates itself through authentic Italian offerings, utilizing a supply chain that imports key ingredients to ensure traditional flavor profiles.”
- A local reviewer rewrite: “Finally, a place that doesn’t just claim to be Italian—they’re using the real deal ingredients shipped over from Italy to make dishes that actually taste like the ones from the old country.”
And so on.
Now, you might ask yourself, “What’s the point?” The Apple and Microsoft rephrasing technique clearly reduced the amount of post-training you’d need to do, by preparing your data to resemble how you want your LLM to act. But here? We’re just restating facts many different ways. Why bother?
To understand why this works, we first have to explain what an epoch is.
An “epoch” is one complete pass through the entire training dataset during the training process. When building an LLM, or any other machine learning model, you usually train for multiple epochs. One pass through isn’t sufficient for the model to learn effectively. Multiple passes allow models to review and refine the patterns observed in the data, reduce prediction errors, and eventually converge towards optimal values. The values in the model change less with each epoch.
One tricky job for the model builder is to train for just the right number of epochs. Too few, and the model hasn’t learned all it can from the data. Too many epochs can cause overfitting: where a model learns the specific patterns in the data too well, rather than generalize rules that work with new data it’s given during usage.
Here’s a rough example: if you ask an overfitted model about a topic, it might simply regurgitate a verbatim Wikipedia article, rather than address your specific question. This can be a problem if you’re being sued for copyright infringement, but it can also cause models to deliver worse answers because they don’t take into account the context they’ve been prompted with and fail to reply appropriately.
Which brings us back to Moonshot: by rephrasing text in various ways, the team can run less epochs on more data. The model will see the same fact several times, but each time will be in a slightly different tone or style; rather than playing back the same sentence over and over.
This approach yielded impressive results against OpenAI’s SimpleQA benchmark:
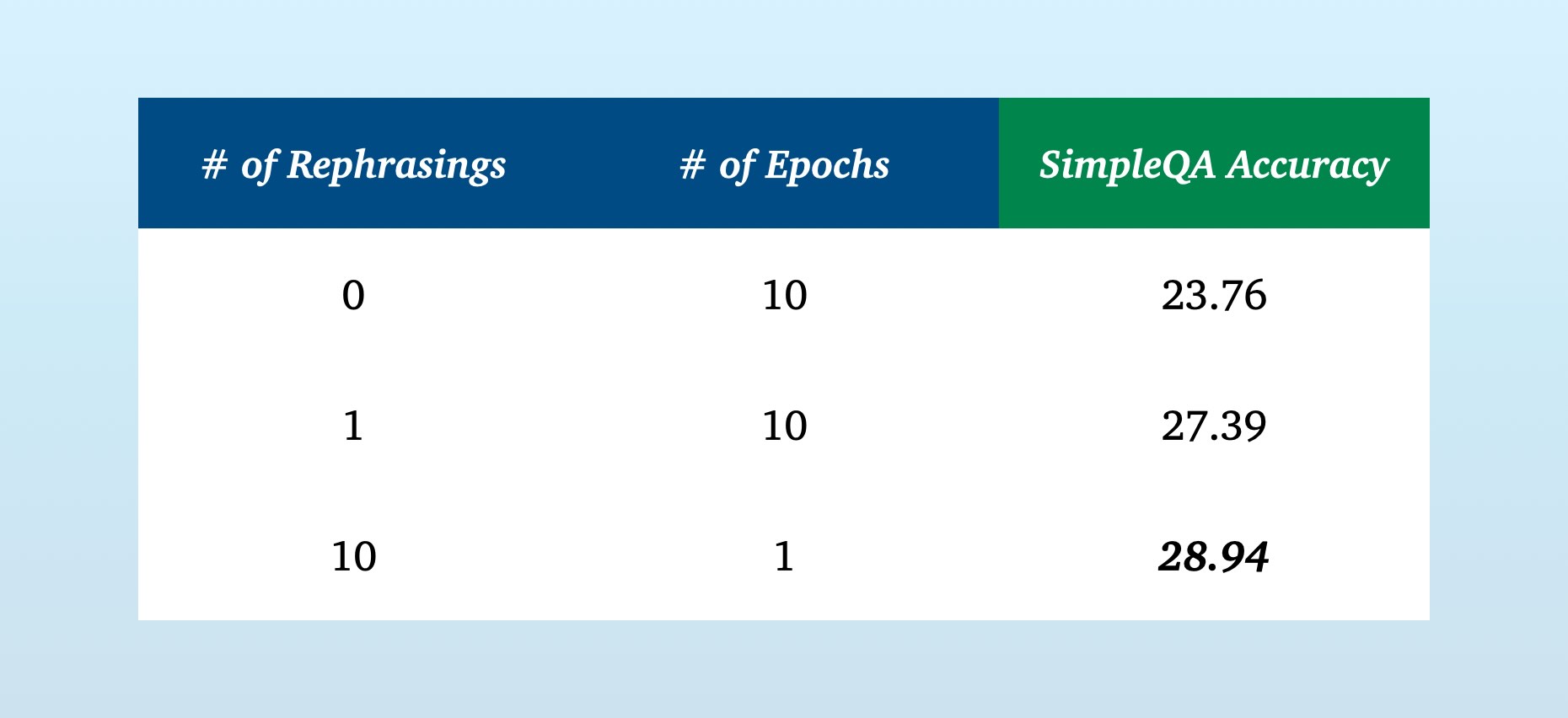
The Kimi team applied a rephrasing technique to “knowledge” content in their training data corpus, rephrasing up to twice. Their method looked like this:
- They developed “carefully engineered prompts” to rephrase text in varied styles and perspectives.
- For longer texts, they chunked the text into segments and rephrased each one-by-one, using the prior chunk’s rewrite as a reference. These rewrites were then stitched together.
- All rephrased contexts were compared to their original texts, using an LLM to verify that the information in each was the same.
Interestingly, the team says they applied a rephrasing technique to math data, but notes further investigation is necessary:
Key challenges include generalizing the approach to diverse source domains without compromising factual accuracy, minimizing hallucinations and unintended toxicity, and ensuring scalability to large-scale datasets.
Ah well, can’t win ‘em all.
For knowledge writing, however, this approach appears promising and easy enough for other model builders to pick up. Avoiding overfitting is a constant challenge, as is having sufficient training data on key topics. By rewriting information in another style or perspective, you can increase your model’s performance and reduce the chances of exact regurgitation.