How Kimi K2 Became One of the Best Tool-Using Models

Continuing our walk through Moonshot AI’s technical paper for Kimi K2, let’s move on from how Moonshine rephrased data during pre-training and look at how they taught Kimi how to use tools better in agentic workflows.
Models Have to Be Taught How & When to Use Tools
I like MCP, but I don’t like that it made everyone think tool use is plug-and-play. Yes, MCP standardizes how we express and add tool functions to our contexts (and remember, it’s one of many), but we still have to provide our model with instructions for when and how to use the tools available to it.
Connecting your model to random MCPs and then giving it a task is like giving someone a drill and teaching them how it works, then asking them to fix your sink. Is the drill relevant in this scenario? If it’s not, why was it given to me? It’s a classic case of context confusion.
The dominant, general pattern for instructing a model with tools is called ReAct, which stands for “reason” and “action.” ReAct isn’t fancy; it’s just a prompting technique. We provide a model with tools, then instruct it to reason about whether it should use these tools to accomplish a given task.
Here’s what a ReAct prompt looks like, as defined in DSPy:
You are an Agent. In each episode, you will be given the fields {inputs} as input. And you can see your past trajectory so far. Your goal is to use one or more of the supplied tools to collect any necessary information for producing {outputs}. To do this, you will interleave next_thought, next_tool_name, and next_tool_args in each turn, and also when finishing the task. After each tool call, you receive a resulting observation, which gets appended to your trajectory. When writing next_thought, you may reason about the current situation and plan for future steps. When selecting the next_tool_name and its next_tool_args, the tool must be one of: {list_of_tools}",
Each of the variables in brackets are replaced with your given inputs, outputs, and tools. The DSPy ReAct module always provides a tool named finish, that lets the model mark its work as done.
ReAct is a prompting technique, similar to Chain of Thought. Just as Chain of Thought was as simple as modifying our prompts, adding, “Think step-by-step,” ReAct is a standard pattern of instructions we can insert into a prompt.
Chain of Thought proved so useful, we ended up training our models to think step-by-step by default, creating reasoning models. ReAct has had similar levels of success – it remains the default approach to tool instructions, since its creation in 2023 – so it’s only natural we’d train it into our models as well.
Training Kimi to Smartly Use Tools
Plenty of models have been trained for tool use. Open models we know have been post-trained include Mistral’s Devstral and Menlo’s Jan-Nano. Moonshot isn’t the first to post-train on a ReAct-style pattern, but it is one of the first to share details.
Here’s what they did:
- Gather a Bunch of Tools: They gathered over 3,000 MCP tools from GitHub repositories, filtering them to ensure their specs were of sufficient quality.
- Generate a Bunch of Synthetic Tools: They categorized the tools they found in step one, identifying clusters using embeddings. They used the categories as inputs to generate over 20,000 diverse kinds of tools, complete with clear interfaces and descriptions.
- Generate a Bunch of Synthetic Agents: They generated thousands of unique agents, each with system prompts and different combinations of tools from steps 1 and 2.
- Simulate Usage of the Synthetic Agents: The team simulated multi-turn tool-use scenarios in order to generate “trajectories” – a fancy way of saying the detailed set of steps documenting the inputs and steps models take to accomplish their goals. Some of these scenarios simulated “users” – fake people with diverse communication styles – interacting with these agents, while others simulated autonomous usage.
- Evaluated & Filter the Trajectories: Finally, all the trajectories were judged by an LLM, removing all trajectories that didn’t meet specific criteria.
Everything about this process, aside from step 1, was simulated. The inputs and outputs of each tool, the people using the agents, and the agents themselves were all invented whole cloth by an LLM.
Even better, for some domains (math and programming), they took the time to build real execution environments and ran actual agents on verifiable tasks. The trajectories generated by this process were then combined with the synthetic trajectories and used during the fine-tuning phase of post-training.
And it worked. Moonshot’s results are really impressive.
Cline, an open-source AI coding tool, put Kimi K2 through the paces and found it to be one of the best tool-using models available. It’s number two on both standard tool-use benchmarks:
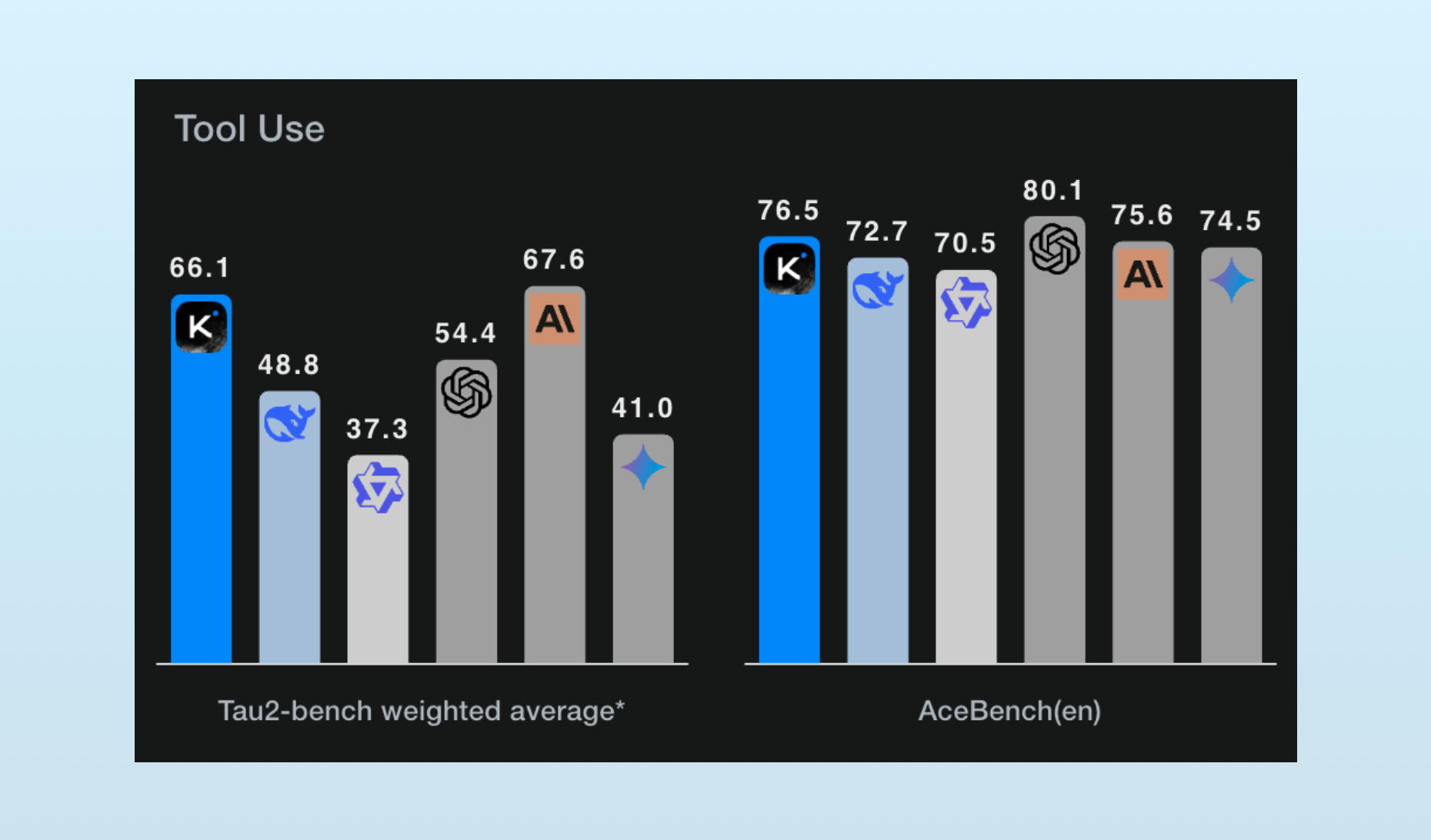
More impressive is how it works during real-world use:
After analyzing over a week of production data from thousands of Cline users, Kimi K2 is delivering surprising results. In real-world diff editing tasks — the complex search-and-replace operations that challenge even frontier models — Kimi K2 is achieving failure rates as low as 3.3%, matching and occasionally outperforming Claude 4 Sonnet.
Remember: Kimi K2 is cheaper to run than Claude 3.5 Haiku, which is a fraction of the price of Sonnet 4.
Recently, I find it helpful to think about post-training as an area of user-experience (UX) work. Perhaps ChatGPT’s breakout innovation was using human-feedback during post-training to teach an LLM model how to converse naturally. And chain-of-thought training during post-training built the reasoning models whose ‘thinking’ improves the often under-detailed prompts users provide.
And in the last few months, we’ve seen post-training build a more programmatic-ish interface into models by training them how to recognize and use tools, essentially building a new surface area for user interaction and design.
Prior to this step, small models have had a devil of a time using tools – an ability MCP was heralded as fixing. Still, heavy prompting is required guide models. To return to our drill and plumbing metaphor from earlier: designers not only have to give a model a drill and explain how to use it; they have to specify when a drill might help. (Even large models have to do this. Remember, the tool instructions in Claude’s system prompt are just as long as the tool definitions themselves.) By building in these abilities during post-training, I’m excited to see smaller models gain more practical utility.