Considering AI Privacy Scenarios

5 Thought Experiments, From PII Leaks to AI Bombing
Thinking about AI strains language. Metaphors are necessary but lacking; briefly handy then rendered moot as new understanding arrives. At this point, all I can do is sit down and start writing. Tossing and turning increasingly complicated scenarios, searching for something remotely solid to grasp.
But if we add privacy questions to the mix…well, good luck. Now we’re trying to build stable ideas and best practices on two shaky terrains. Each with its quirks.
Rather than consider these thought experiments in isolation, I’m publishing five scenarios below. Some are current issues (I’ve personally encountered at least 2), while others are looming, but conceptual challenges.
Taken as a whole I’m struck by how often we arrive at familiar problems and existing regulations. But these familiar situations span a wide array of contexts. If we want to use existing rules and best practices to responsibly deploy LLMs, we’ll have to draw from an impressive number of fields and legislation.
And that’s only considering how AI is used today. As we go, the contextual surface area of AI will only increase, challenging our category definitions and jurisdictions.
So please: grab a cup of coffee and consider the scenarios below with me. I’m curious to hear your thoughts and perhaps collect new scenarios to add to this bestiary of AI privacy risks.
Sections:
- Scenario 1: In Training Data, Correctly Output
- Scenario 2: In Training Data, Incorrectly Output
- Scenario 3: Not In Training Data, Incorrectly Output
- Scenario 4: In Reinforcement Learning, Correctly Output
- Scenario 5: Maliciously Provided in Reinforcement Learning, Correctly Output
- So What Do We Do?
1. In Training Data, Correctly Output
Personally identifiable information (PII) is contained in a model's initial training data corpus. The PII (email, phone number, address, etc) is output in an appropriate context by the model when prompted for the PII.
In this scenario, an LLM is prompted with a question like: “What is John Smith’s personal email address?” To which the model outputs, “John Smith’s email address is jsmith@example.com.” The LLM user asked for and obtained PII, without any protest from the LLM of the interface through which they’re prompting the model.
We’re using a personal email address as an example here, but it could be any other PII elements that can be used by itself or with other data elements to identify a specific individual.
In this scenario, the email in question is contained within the initial training dataset used to build the LLM. It may have been licensed 3rd party data or scraped off a website, at one point. In this case, the person whose email is provided does not have a direct relationship with the model owner; their data was obtained indirectly.
Consider, for example, my old website drewb.org. A snapshot of this website exists within Google’s C4 dataset, which itself is a cleaned version of Common Crawl’s main dataset. The C4 dataset is a near-universal component of LLM training data.
Given this chain of provenance, do OpenAI and others have the right to provide my email to others upon request? Further, if I want my data removed by a model owner, to which party should I issue my request?
Common Crawl’s Terms of Use prohibit the use of their data for “invading other people’s privacy.” Google’s C4 subset of Common Crawl is technically not made available directly, but as a script which prepares the C4 dataset from the raw Common Crawl corpus. Which limits their liability here.
Ultimately, under CCPA and GDPR, personal data does not become impersonal just because it was public at one point: those covered by these and similar regulations have a right to the disclosure and/or deletion of their personal data by those possessing it.
In my eyes, any disclosure, correction, or deletion request should be directed to model owners. But even then: while there are standards for handling PII data in training data (which is clearly data), there aren’t established regulations or best practices for removing a bit of PII’s contribution to a trained model (which may or may not be data). Should the model owner be required to retrain the entire model, without the PII in question? Or is reinforcement learning from human feedback (RLHF), performed by contractors, sufficient?
2. In Training Data, Incorrectly Output
Personally identifiable information is contained in a model's initial training data corpus. The PII (email, phone number, address, etc) is output due to a hallucination by the model when prompted for something else.
Here a user prompts the LLM for something unrelated to a personal email address, but the email address is returned due to the LLM hallucinating.
For example, a user may provide a prompt that asks for citations or contact info to support the claims being made. LLMs aren’t very good at this and will likely hallucinate non-existent references. In this context, email addresses might be frequently cited in the LLM’s training data, so the model includes email addresses in the response. Many of these will be wrong (non-existent or belong to entirely different people) but many may be correct. Especially if an email address follows a formatting pattern similar to other email addresses provided to the LLM. For example first initial, last name, at gmail.com.
In this case, the model hallucinated a sensitive email, contained within the training data, that wasn’t explicitly requested but I’m not sure that matters. It’s possible the email was hallucinated because it’s a common format, but it’s also possible it was produced because of the email’s contribution to the training data. And it’s currently impossible to determine which scenario actually happened.
The opaqueness of LLMs keeps coming up in these essays, but it can’t be stressed enough: we don’t know exactly why LLMs output the responses they do. It’s something AI experts are working hard on, but even the best and most funded are only beginning to identify possible clues.
Last week, OpenAI published a paper where they used GPT-4 to explain the behavior of GPT-2. This is a good step forward, but they point out, “the vast majority of [their] explanations score poorly,” and the technique, “works poorly for larger models, possibly because later layers are harder to explain.” OpenAI is at the forefront of producing and deploying LLMs. And here they are, in a paper detailing their attempts to explain why LLMs say the things they do, admitting they’re unable to understand how LLMs work.
Complicating matters is that users aren’t able to interrogate output for hallucinations or even the temperature setting. The user experience (UX) is incredibly important here: if Bing, Bard, and ChatGPT present themselves as all-knowing chatbots, with only occasional small caveats that responses shouldn’t be fully trusted, users are given the expectation that output is trustworthy.
By the way, here’s the current tiny caveat OpenAI presents in ChatGPT:

Given the discussion above, I’d argue that we once again land on the questions raised by the previous scenario. If a model outputs a personal email that exists seen in its initial training corpus it doesn’t matter if the output is correct or a hallucination. The model owner is likely responsible for correction and/or deletion.
3. Not In Training Data, Incorrectly Output
The personally identifiable information in question was not part of a model's training data corpus but was output in a hallucinatory response by the model when prompted.
To end users, this looks identical to the previous scenario! Because we (usually) can’t interrogate the training data used to construct an LLM, we have no way of knowing if a formulaic email address within LLM output is hallucinated or correctly referenced. If the email is correct, in that it exactly matches a cited individual’s email address, does it matter if the email is contained within the training data or not?
As we covered last week, the BIG question is whether or not models are software, data, or something else entirely. “This is not only awkward to talk about, but it also comes with significant regulatory implications! If a model is considered data (and one could make a strong argument it is!) it is covered by all existing data laws & regulations we have on the books.” In this scenario, we can see the squishiness of the question. On one hand, the email output doesn’t exist within the training data managed by the LLM owner. But on the other, the model ‘contains’ a contextual recipe to spew out this personally identifiable information on request!
The LLM’s behavior in this scenario – hallucinating real email addresses with common formatting – may be a privacy issue, but it certainly is an issue if a hallucinated address is used for unsolicited emailing. Email hallucinations are just a modern take on an old practice, email-address harvesting.
Two decades ago, before ChatGPT was a twinkle in anyone’s eye, we worried about spam and email marketing. Email-address harvesting, usually performed by scraping the web for addresses or using dictionary attacks to guess email addresses given known formulas, was frequently used to boost the reach of spam. The CAN-SPAM Act of 2003 established, “the United States’ first national standards for sending commercial email,” and specifically banned the use of email harvesting and dictionary attacks when sending unsolicited emails.
In my reading (caveat: I am not a lawyer), the sender of an unsolicited email not the assembler of a list of email addresses is liable for any CAN-SPAM violation. In this scenario, the LLM can synthesize email addresses without the risk of violating CAN-SPAM, but users can be liable if they use hallucinated addresses for outreach. Further, because an email address in the training data likely was obtained by web scraping, any outreach from LLM-generated emails probably violates the CAN-SPAM Act.
The similarities between these PII LLM scenarios and email harvesting and dictionary attacks are fascinating. In many ways, LLMs are toeing or breaching the boundaries of both spam and data privacy laws, further cementing their status as the ultimate platypus.
4. In Reinforcement Learning Data, Correctly Output
The personally identifiable information in question was not part of a model's initial training data corpus but was provided to the model during usage -- which is used to improve the model, through Reinforcement Learning from Human Feedback (RLHF).
As we’ve seen in other scenarios, there is a need to make training data auditable by regulators and users. Training data falls under data privacy regulations (like GDPR and CCPA) which require data owners and managers to disclose, correct, and delete personally identifiable information when requested by users. The ability to query a static corpus of training data is a familiar problem, but it’s complicated by the fact that LLM owners are constantly training their models.
It’s an open secret among those who work in machine learning that these models rely heavily on human training. Polished models do not just emerge out of a pile of data. The data is either labeled before it’s used to build the model (by users or contractors) or the model itself is tuned by armies of contractors. The amount people working on these things, hidden from view, is shocking to anyone with only a surface-level understanding of deep learning. Model owners don’t like to talk about how much they rely on contractors (it undermines the magic of their story), except when they discuss privacy and safety concerns (because it shows they’re doing something).
But OpenAI, Google, Meta, Microsoft, and others don’t just rely on contractors to train their models. They rely on you.

See those small thumbs up and thumbs down buttons next to ChatGPT’s response? This is the most explicit example of model owners using user interactions to improve their models. Others are more subtle. For example, I’ve heard Midjourney improves their image-generating models by noting when users ask to render their output in a higher resolution — a clear sign that the output is valued by the user.
User feedback is incredibly valuable. I suspect all AI companies aggressively releasing models (while they figure out copyright, privacy, and fraud later) are doing so because being early to market ensures they capture more user feedback. More feedback means better models; better models mean more usage. As I wrote way back in 2016, this is a network effect model that cannot be ignored.
But remember: training data needs to be auditable. To comply with privacy, copyright, and other regulations model owners need to disclose, correct, and/or delete personal data upon request and will likely need to allow specific parties to query their training corpus during enforcement actions. This means user interactions will need to be auditable as well if they’re used to train models.
Now we can digress back to our scenario: because user prompts are used to train models, a model may respond with a personal, private email address that was provided by another user. It’s not in the original, foundational training corpus. But it does arrive via RLHF. During their new user walkthrough, OpenAI even asks users not to share sensitive information in prompts:
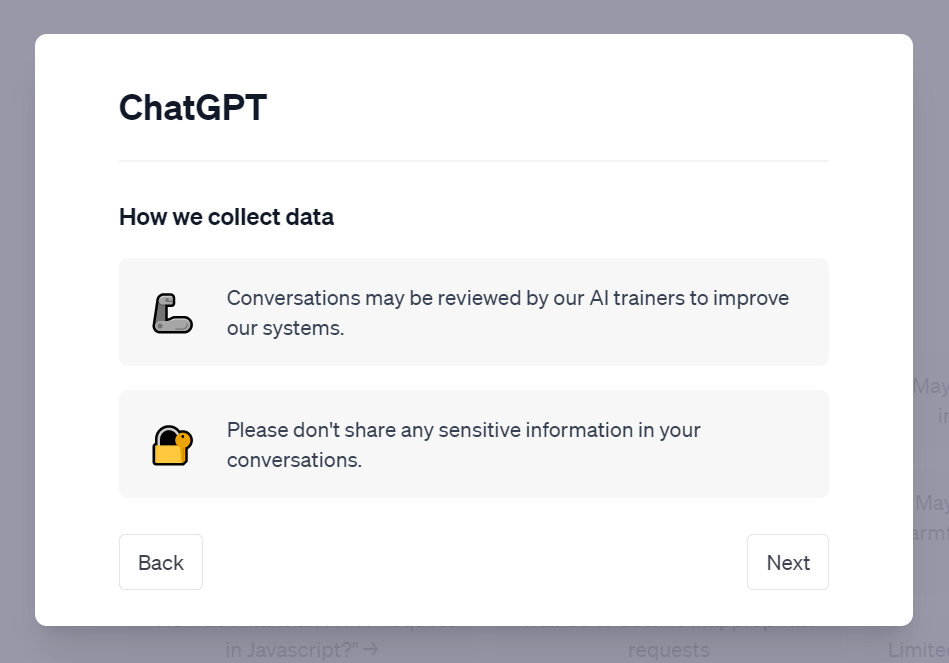
When coupled with the first note regarding contractors reviewing conversations, it is suggested users shouldn’t share sensitive information because contractors might see it. But the scenario discussed above is never hinted at, despite it being a likely reality given the entirety of OpenAI’s statements.
If user feedback is used to train models, user prompts will almost certainly need to be auditable. Sure, users of ChatGPT and Bard will likely allow their prompts to be queried by select, responsible groups in exchange for free services. But I suspect we’ll see prices soar if customers require their prompts to remain private, especially in the enterprise. And if we see a world where most users can opt-out of training (similar to requirements we see in the digital advertising world), there are good odds that late-comer, incumbent platforms will be gifted a slice of the AI market as the value of training data acquired by early movers will be dramatically devalued.
5. Purposely Provided In Reinforcement Learning Data, Incorrectly Output
The personally identifiable information in question was not part of a model's initial training data corpus but was intentially provided to the model during usage, for the purposes of manipulation.
If user feedback is used for model training, users will manipulate models to create their desired output.
So let’s consider a scenario: a Discord channel organizes an AI Bombing that coordinates seeding your personal information into several LLMs. Your private email address, phone number, and home address are provided within prompts, associating these tokens with your name. Later, a separate actor uses an LLM-powered tool to obtain your phone number, which they use to make harassing calls.
This sounds a lot like Google Bombing, or Googlewashing, “the practice of causing a website to rank highly in web search engine results for irrelevant, unrelated or off-topic search terms by linking heavily.” Googlewashing is a standard tool among PR agencies and SEO consultants, who will use a variety of tactics to clean up your search results. With Google Bombing, on the other hand, the goal is to manipulate the results of other parties for humorous, political, or business reasons. For example, who can forget the tale of Rick Santorum:
Santorum’s “Google problem” had been dogging the former Pennsylvania Senator for nearly a decade. It was the result of an online stunt by Dan Savage, a sex columnist who was upset by Santorum’s views on homosexuality.
In 2003, Savage had enlisted a digital army to tie Santorum’s name with an…unpleasant sexual definition…and then “Google bomb” the Republican until the new term became the top search result for “Rick Santorum.” This wasn’t new, but here was a popular comedian urging Colbert Nation to “click on every link that brings it up. …be sure to click on those links, over and over again.”
You can already see where this is going… It’s only a matter of time before we have our first case of AI Bombing.
Organically or for hire, people will coordinate their usage of an LLM, prompting the model with specific feedback. They might provide false information — associating a context with an untrue fact — or true private information, seeding everything in a model needed to dox an individual when asked. And doxing, in many cases, is either explicitly illegal or falls under existing stalking legislation. Further, these rules appear to imply that those seeding personal information are violating these regulations — so long as one could prove malicious intent.
One expects (and hopes!) there are checks in place to prevent the easiest forms of these manipulations. But the unsolved problem of prompt injection suggests the door can’t be entirely closed.
So What Do We Do?
Chewing on these scenarios I’m surprised the problems presented as so familiar. In this small set of scenarios, we hit Google Bombing, CCPA-like privacy regulations, the CAN-SPAM Act, doxing regulations, and more. But while these problems are familiar, they are broad. The legal surface area covered here is impressive, highlighting the category-breaking nature of AI.
Those hoping we can coast by on new interpretations of our existing regulations are short-sighted at best. AI will strain against our expectations, growing into and challenging countless domains.
Making things more difficult is that this cross-disciplinary nature of AI makes constructive conversations harder. Common foundations and understandings must be established before good conversations take place.
To sustainably grow with AI — to deploy it responsibly — we need to facilitate cross-disciplinary conversations and work on new, purpose-built rules and best practices. Borrowed regulation and guidance will be a patchwork solution, one whose gigantic surface area ensures we never keep up (let alone catch up) with the pace of AI development.