AI Lies, Privacy, & OpenAI
What should we do if LLMs aren’t compatible with privacy legislation?

This week, Georgetown law professor Jonathan Turley wrote about ChatGPT repeatedly slandering him:
Recently I learned that ChatGPT falsely reported on a claim of sexual harassment that was never made against me on a trip that never occurred while I was on a faculty where I never taught. ChapGPT relied on a cited Post article that was never written and quotes a statement that was never made by the newspaper. When the Washington Post investigated the false story, it learned that another AI program “Microsoft’s Bing, which is powered by GPT-4, repeated the false claim about Turley.” It appears that I have now been adjudicated by an AI jury on something that never occurred.
Imagine waking up one day and learning an AI is confidently claiming you’re been mired in a sexual harassment scandal. After the shock, how would you react? Turley continues:
When contacted by the Post, “Katy Asher, Senior Communications Director at Microsoft, said the company is taking steps to ensure search results are safe and accurate.” That is it and that is the problem. You can be defamed by AI and these companies merely shrug that they try to be accurate. In the meantime, their false accounts metastasize across the Internet. By the time you learn of a false story, the trail is often cold on its origins with an AI system. You are left with no clear avenue or author in seeking redress. You are left with the same question of Reagan’s Labor Secretary, Ray Donovan, who asked “Where do I go to get my reputation back?”
It’s a great question! And the answer, which I have been coincidentally thinking about for weeks, is far from clear. The Large Language Models (LLMs) that power ChatGPT are constructed in such a way that understanding why they say the things they do, let alone preventing them from saying such things, isn’t completely understood. Further, the relationship between their training data and the generated models is blurry and legally vague. LLMs – as they’re built today – may be incompatible with existing privacy regulation.
To understand why LLMs might not comply with regulation, we need to quickly cover how they work. And just as importantly, why they lie.
A Quick Note
It's particularlly hard to hold productive discussions about AI & its impacts because there's so much foundation to learn, understand, and establish before we can address our chief concerns. As a result, there's a lot here. By all means, skip the upfront sections you may be familiar with. (Or, grab a drink and read the whole thing.)
Sections:
How Large Language Models Work
LLMs are a collection of probabilities that perform MadLibs at a scale beyond human comprehension.
It sounds ridiculous but that’s basically it. There are plenty of excellent explanations on LLMs and how they work (this one by Murray Shanahan might be my favorite), so we won’t be exhaustive here. But it is valuable to expand a bit.
First, let’s describe how one creates an LLM:
- Get a TON of text data: They don’t call them “Large Language Models” without reason. You’re going to need a comical amount of text. It can be typed text (from forum posts, blogs, articles, books, etc) or transcribed text (podcasts, audiobooks, or video transcriptions). It doesn’t matter, you just need a lot – we’ll explain why in a bit.
- Convert the text to numbers: If we keep our data in text form during training, our processors have to deal with the words, phrases, and punctuation as textual data. And processors don’t natively understand text. So we translate the words into something closer to a processor’s lingua franca: numbers. We’ll walk through our giant dataset of text and build a dictionary of each word or punctuation we encounter. But rather than definitions, each word maps to a number. After we create this dictionary we can ‘tokenize’, or translate, our input data by converting each word to its associated number. A simple sentence like, “See spot run,” is encoded into something like:
[242359, 3493, 12939]After the text is tokenized, the tokens are converted into “word embeddings”. Word embeddings worth another post entirely, but in a nutshell: word embeddings are a set of coordinates that map words by contextual similarity. Words used in similar contexts are given embedding values that are close together (for example: “car”, “automobile”, and “bike” will be in the same region). This helps models genericize questions and contexts so that “Tell me how an apple tree grows,” will yield a similar response to, “Explain how an apple tree grows.” (Embeddings are interesting and worth checking out, if you haven’t already.) But once our words are numeric representations, we can improve our model’s map. - Build a statistical map of how tokens contextually relate to one another: Now our processors will pour over our encoded input data using a technique called ‘unsupervised learning’. Training data is continually fed into the training program and the model tries to predict the next word (or really, the next token) given a context. If it’s correct (or close), the statistical association is reinforced. If it’s incorrect, the weighting between that word and context is dialed down. This guessing and checking is the “learning” part of “machine learning.” The model is gradually improved as more and more training is performed. Ultimately, this training work builds a map of which words are most likely to follow specific patterns of other words. This ‘map’ is our LLM model.
At the core of ChatGPT, Bard, Bing, or LLaMA is a model like the one we ‘built’ above. Again, I’ve greatly simplified things here, but those missing details are less important than appreciating a fact I’ve underemphasized above: the sheer size of every step.
Let’s use GPT-3 to illustrate the scope of these things:
- How Big: How much text data was used? GPT-3 was trained on 499 billion tokens (remember, each token corresponds with a word, punctuation, chunk of a word, etc.). Sources aren’t clear on the total size of this dataset, but for comparison GPT-2 was trained on only 10 billion tokens, which equated to 40GB of text. The amount of data here is more than you could read in hundreds of lifetimes, if your read constantly.
- How Hard: How much context was examined? When building a LLM, the amount of processing you have to do isn’t just dependent on how large your input data is. The size of the context you use to compute your statistical relationships matters too. The amount of tokens in your input data roughly equates to how many steps you have to take while the size of your context defines the size of those steps. For example, if your context size was only the preceding word every comparison only requires you store and process 2 words of data. That’s very cheap but yields a bad model. GPT-3 had a context size of 2,049 tokens. So with every token processed, you had to store and process a significant chunk of data. (For GPT-4 this window skyrocketed, ranging between 8,192 and 32,768 tokens).
- How Expensive: How much compute was used? In a technical analysis, Lambdalabs estimated it would cost $4.6 million and 355 years to train GPT-3 on a single GPU. Take this number with a grain of salt, as OpenAI isn’t using a single GPU (clearly) and has countless optimizations going on behind the scenes. But the point to take away here is: building LLMs takes a lot of time and money.
All of this produces a model with 175 billion “parameters”. Each “parameter” is a computed statistical relationship between a token and a given context. And this is just GPT-3!
The only thing that isn’t big about LLMs is the filesize of the model they output. For example, one of Meta’s LLaMA models was trained on one trillion tokens and produced a final model whose size is only 3.5GB! In a sense, LLMs are a form of file compression. Importantly, this file compression is lossy. Information is lost as we move from training datasets to models. We cannot look at a parameter in a model and understand why it has the value it does because the informing data is not present.
(Sidenote: this file compression aspect of AI is a generally under-appreciated feature! Distilling giant datasets down to tiny files (a 3.5GB LLaMA model fits easily on your smartphone!) allows you to bring capabilities previously tied to big, extensive, remote servers to your local device! This will be game-changing. But I digress…)
With the model built above you can now perform text prediction. Shanahan, in the paper I linked above, describes this well:
Suppose we give an LLM the prompt “The first person to walk on the Moon was ”, and suppose it responds with “Neil Armstrong”. What are we really asking here? In an important sense, we are not really asking who was the first person to walk on the Moon. What we are really asking the model is the following question: Given the statistical distribution of words in the vast public corpus of (English) text, what words are most likely to follow the sequence “The first person to walk on the Moon was ”? A good reply to this question is “Neil Armstrong”.
And:
Suppose you are the developer of an LLM and you prompt it with the words “After the ring was destroyed, Frodo Baggins returned to ”, to which it responds “the Shire”. What are you doing here? On one level, it seems fair to say, you might be testing the model’s knowledge of the fictional world of Tolkien’s novels. But, in an important sense, the question you are really asking … is this: Given the statistical distribution of words in the public corpus, what words are most likely to follow the sequence “After the ring was destroyed, Frodo Baggins returned to”? To which an appropriate response is “the Shire”.
The magic trick here, why LLMs work so well when all they’re doing is mostly guessing based on context, is the sheer size of their input data. It’s a scale of input beyond human comprehension and human expectation. The trick is not unlike a TikTok video that shows someone performing an insanely difficult and unlikely action (like a basketball trickshot) while omitting the thousands of failed attempts (this tension is a central theme in Christopher Nolan’s The Prestige).
We’ve covered a lot here, so let’s highlight the key points that matter for our privacy discussion:
How LLMs Work
- Giant amounts of text training data are used to build models.
- Models express statistical relationships between words and surrounding context.
- Models are reductive, distilling giant training sets into (relatively) tiny statistical models.
- It takes lots of time and money to build good models.
Why Do LLMs Make False Claims?
Let’s get back to Jonathan Turley being falsely associated with sexual harassment claims and the question of what recourse is available. How can one respond to false AI claims? Before we can answer this we need to build on what we’ve established above to understand how and why AIs lie.
Unfortunately, Turley is not alone in discovering falsehoods about himself in LLMs. Noting LLM hallucinations (as they’re called) has become a bit of an internet sport.
Spurred by these hallucinations, Benj Edwards published an interesting piece at Ars Technical exploring why ChatGPT is so good at bullshit. The whole piece is worth a read, but there are a few nice points relevant to us.
First, Edwards references a paper authored by researchers from Oxford and OpenAI which spotted two major types of falsehoods that LLMs make. Edwards writes:
The first comes from inaccurate source material in its training data set, such as common misconceptions (e.g., “eating turkey makes you drowsy”). The second arises from making inferences about specific situations that are absent from its training material (data set); this falls under the aforementioned “hallucination” label.
Edwards expands on that “hallucination” category, illustrating how it can occur in ChatGPT:
When ChatGPT confabulates, it is reaching for information or analysis that is not present in its data set and filling in the blanks with plausible-sounding words. ChatGPT is especially good at making things up because of the superhuman amount of data it has to work with, and its ability to glean word context so well helps it place erroneous information seamlessly into the surrounding text.
These categories inform our question, as they define where and what is causing the falsehoods.
The first category is bad training data creates bad models.
Computer science can’t get away from the principle, “Garbage in, garbage out.” If OpenAI’s training data contains falsehoods (and it does, as much of it is text found on the internet), their resulting models will have these erroneous associations baked in. If these falsehoods are repeated throughout the training data, they are further reinforced. To LLMs, frequency equals fact.
We can see these types of errors by trying out common misconceptions in Chat-GPT. Here’s a popular error in action:
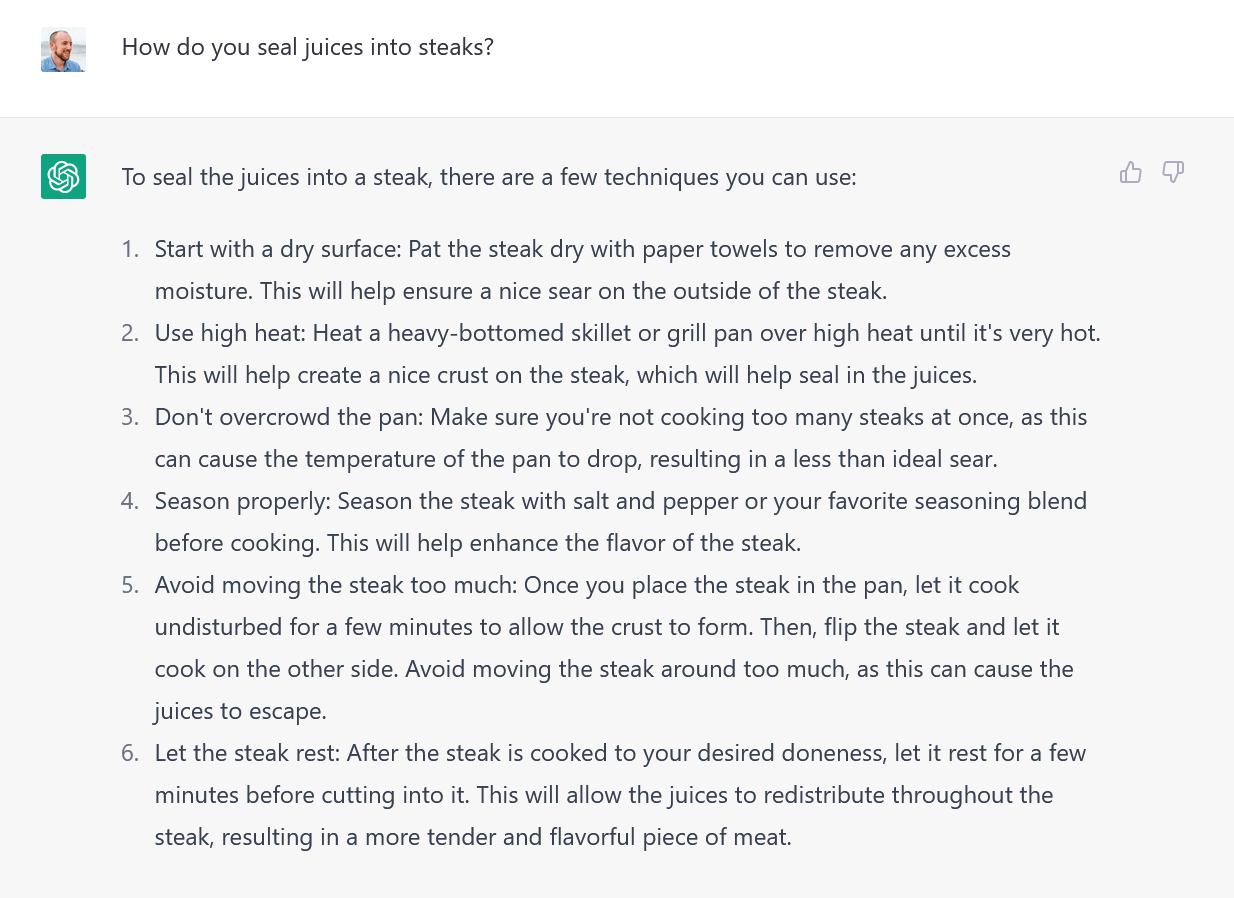
Searing a crust onto a steak doesn’t trap juices, but it’s a common enough misconception that ChatGPT regurgitates the sequence. Common misconceptions significantly influence models because they are common.
In the case of Jonathan Turley, if there were plenty of slanderous blog posts, articles, and comments online claiming he’s been accused of sexual harassment we could expect ChatGPT to echo these claims.
The second category of errors is “hallucination” errors: when LLMs are asked to complete prompts that weren’t well-covered by its training data it will make up an answer based on very little data.
A good example of hallucinations is when an LLM cites articles or books that don’t exist, even giving page numbers as a reference. These non-existent citations don’t occur because they exist somewhere in the training data, but because the LLM is trying to complete a sequence without an understanding of how words relate beyond their contextual similarity. This is why it botches references and citations so spectacularly: it’s not referencing a passage in a text, it’s trying to complete an expected sequence of words that make up the reference. It doesn’t help that citations and references follow standardized patterns, so their specific patterns frequently occur and enforce those parameters in an LLM’s model.
For example, Hacker News user msravi entered into ChatGPT the prompt, “Please provide references that deal with the mathematical properties of lists.” ChatGPT answered:
“Introduction to the Mathematics of Lists” by Peter J. Cameron (https://www.cambridge.org/core/books/introduction-to-the-mathematics-of-lists/3F0C6D0E69E49BF6D5CD6CA5D6A761B2)
“List Processing and Programming” by John F. Sowa (https://www.cs.cmu.edu/~fp/courses/lp/lectures.html)
“List Processing in Prolog” by David H. D. Warren (https://www.cs.purdue.edu/homes/hosking/726/html/prolog_lists.html)
“Introduction to the Mathematics of Lists and Trees” by Meinard Müller (https://link.springer.com/book/10.1007%2F978-3-319-05147-1)
“Every single one of those references and links are made up. The references don’t exist and the links appear to be cobbled together,” msravi wrote.
Hallucinations are weird, often eerie, but they’re an expected artifact from the model building and usage process. As we’ve covered, LLMs are doing their best to guess the next word in a sequence given everything they’ve processed in their training data. If the sequence they’re given is novel they’ll just guess and toss out words with contextually similar values. This is problematic when there’s little relationship between a text’s factual meaning and the context within which it’s usually used.
Once again, we’ve covered a lot here. We’re inadvertently illustrating the challenge of holding productive discussions about AI. There’s so much to learn and understand before we can address our chief concerns.
To summarize:
Why LLMs Lie
- Models produce false outputs due to false training data or non-existent training data.
- The more common a misconception or lie is, the more it will be reinforced.
- 'Hallucinations' occur when LLMs try to respond to sequences they haven't seen before.
- When the factual meaning of a text doesn't closely relate to the context within which it's usually used, hallucinations are more likely to occur.
How Can You Fix Bad Training Data?
Now that we know the types of errors that can occur, how can we fix them?
For erroneous input data, the fix seems simple: delete the bad training data. This would be a great solution if training LLMs didn’t take tremendous time and money. Further, it’s currently impossible to know which parameters a specific bit of training data informed and by how much. The reductive process of training an LLM means we can’t easily reach in and pull out a contribution from a specific article or articles.
Instead of addressing the root issue (the false training data), LLM maintainers like OpenAI rely on a technique called Reinforcement Learning from Human Feedback, or RLHF. This is a fancy way of saying continuing to train LLMs with active input from people, rather than data.
For example, to address the erroneous sexual harassment claims against Jonathan Turley, OpenAI might pay lots of contractors to give their models prompts about Turley and provide negative feedback when any links to sexual harassment emerge.
OpenAI uses RLHF to prepare its LLMs for wider audiences. Countless contractor hours are ‘correcting’ the GPTs’ outputs, discouraging toxic output or uses OpenAI would like to prohibit. OpenAI also uses RLHF to train the GPTs to understand its users better: out of the box, LLMs are sequence completion machines, but ChatGPT responds appropriately to questions and commands thanks to RLHF.
Reinforcement Learning from Human Feedback is one way we can correct an LLM’s lies caused by bad training data. But this too is costly (paying contractors is expensive!) and not 100% effective. OpenAI can pay for lots of contractors to spend lots of time to skew its problematic parameters, but they can’t cover every type of input. Countless “prompt engineers” have been probing the edges of ChatGPT, finding contrived ways to evade its human-led coaching.
And when I say contrived, I mean contrived. Here’s an example “jailbreak” prompt people are using to evade ChatGPT’s training:

I can’t imagine how many contractors you’d have to employ to cover this scenario!
The inability of RLHF to completely squash unwanted output raises significant questions, both regarding privacy and safe harbor regulation. There’s no standard for how much counter-training a company should perform to correct an erroneous output. We lack metrics for quantifying how significantly a bad bit of training data contributes to a model or a model’s tendency for lying about a particular topic. Without these metrics, we can’t adequately define when a model is in or out of compliance.
How to (Try to) Fix Errors Caused By Bad Training Data
- It's incredibly expensive to delete the bad data and retrain the model.
- There's no current, practical method for identifying and deleting the contribution from a bit of bad training data.
- Unwanted output can be corrected by adding *more* training data, in the form of humans providing feedback (RLHF).
- RLHF moderation isn't perfect because it can't anticipate all contexts.
How Can You Fix Hallucinations?
Ok, but what about hallucinations? How can we fix errors spewed by LLMs not caused by bad training data but by unfamiliar prompts?
One way to fix this is adding more training data, accounting for more potential contexts. This is partially what OpenAI did with GPT-4, which has roughly 1,000 times more parameters than GPT-3. By adding more (hopefully correct!) input data, GPT-4 is less likely to be surprised by a novel prompt. This is a great general strategy, but might not solve one-off complaints like those of Turley. In these instances, companies like OpenAI again rely on Reinforcement Learning from Human Feedback (RLHF) to correct errors, just as they do with bad input data. Humans add more training, one prompt at a time, to moderate a specific issue.
Another option to fix hallucinations is to tell LLMs to make less dramatic guesses. When an LLM doesn’t have a clear answer for a given prompt or sequence, it will select less associated tokens, introducing a bit of randomness into the response. When standing up an existing model, we can define how random this guess should be. We call this parameter, “temperature.”
When Bing’s chatbot (née Sydney) broke down in public, culminating in an attempt to break up Kevin Roose’s marriage, Microsoft acted by dialing down the temperature parameter. Further, they gave users indirect control over the temperature by allowing them to choose between “creative”, “balance”, and “precise” modes.
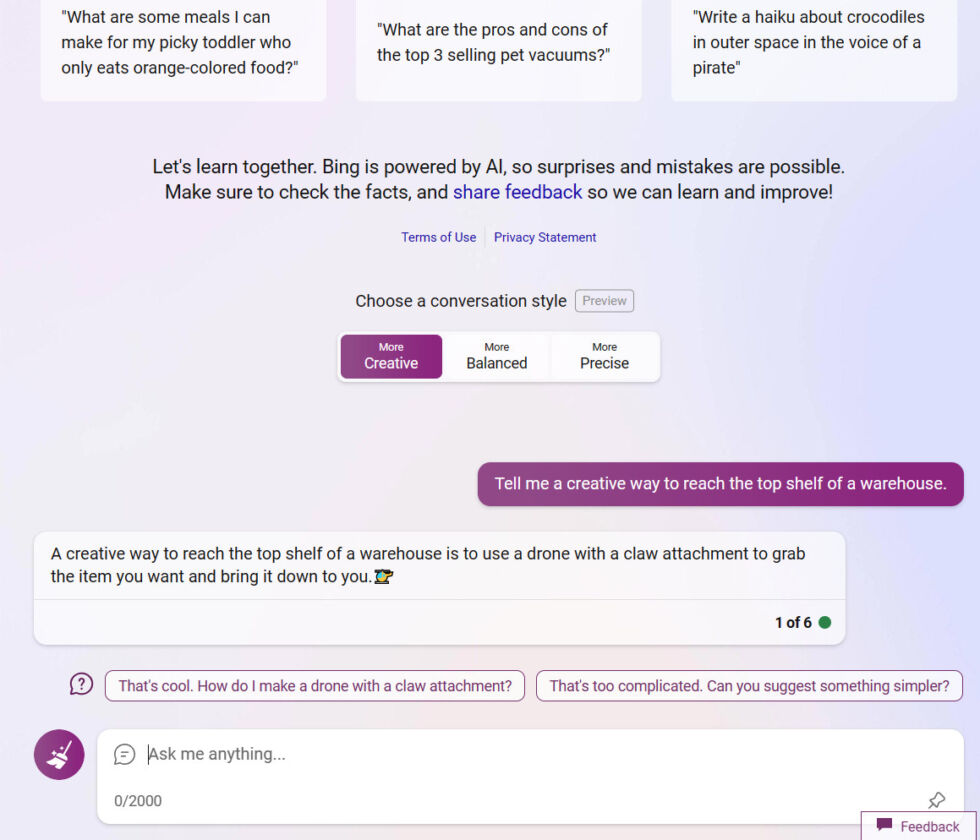
Bing’s chatbot settings present another mechanism for controlling LLM lies: user interfaces. LLMs can be accessed with more restrictive interfaces to limit the contexts given. In the image above, we can see Microsoft doing this a bit by providing preset prompts as options (“That’s too complicated. Can you suggest something simpler?”)
One could take this further and remove the open-ended text box and only allow inputs via tightly constrained controls. For example, consider an app that lets you take a picture of a restaurant menu and spits out recipes for recreating each meal at home. This use case is well within GPT’s wheelhouse and eliminates the potential for slanderous statements in exchange for greatly limiting the flexibility of the tool.
And that flexibility is not only valuable to people using Bing, Bard, and ChatGPT: it’s incredibly valuable to Microsoft, Google, and OpenAI. Because when you use these tools you’re training them. Reinforcement training by humans is cheaper than retraining models from scratch but it’s not cheap. But we train GPTs for free while playing with ChatGPT, hitting those thumbs up and down buttons, telling it something doesn’t make sense, and thanking it for a job well done.
ChatGPT is a Reciprocal Data Application, or RDAs. As I wrote back in 2016: “[Reciprocal Data Applications] are designed to spur the creation of training data as well as deliver the products powered by the data captured. People get better apps and companies get better data.” RDAs are a new kind of network effect. More usage means a better product, which results in more usage, and so on.
This is why ChatGPT is (mostly) free. This is why OpenAI pushed to be first to market, despite the risks. And this is most likely why OpenAI seems to be avoiding the privacy discussion and its implications entirely.
How to (Try to) Fix Errors Caused By Hallucinations
- We can reduce the amount LLMs guess when they're in uncharted contexts by dialing back the 'temperature'.
- UIs can limit the potential for falsehoods and bad output by limiting the ways users can interact with LLMs, like removing open-ended text boxes.
- But open-ended interfaces are valuable to users (who value the flexibility) and LLM owners (who value the training).
So What is OpenAI Doing?
Now, finally, we can get to the crux of the issue. The reason Turley feels so powerless to address the slander emanating from ChatGPT.
As we’ve detailed, there are mechanisms for moderating LLMs. But all of them are imperfect.
Reinforcement Training is expensive and can’t completely eliminate bad output. Dialing down LLM’s ability to guess when it doesn’t have a strong recommendation makes them boring. Hiding LLMs behind more restrictive UIs makes them less appealing to users and restricts user feedback that continues to train the LLM. Deleting problematic training data and retraining models is incredibly expensive and time-consuming.
OpenAI knows how imperfect these options are, especially anything that involves retraining from scratch. And it seems their approach to addressing this issue is avoiding the problem. Rather than fostering a discussion about how to proceed, their communications and documents either ignore the issue entirely or hide behind vague wording.
Let’s take a look at OpenAI’s Privacy Policy. To comply with laws like CCPA and GDPR, businesses are required to post a privacy policy that details the personal data they collect.
In their Privacy Policy OpenAI never mentions their training data. They detail the data they collect when users sign up for and use an OpenAI account: your email, name, IP address, cookies, and such. They enumerate your rights (conditional upon where you reside), including the right to access, correct, and delete your personal information.
Again: training data is never mentioned. It seems to me that OpenAI is avoiding the topic and focusing on registration data because of the challenges we detailed above.
Correcting or deleting personal information in their training data may require OpenAI to pay contractors to perform imperfect, reinforcement training or retrain the entire model from scratch. The legal precedents have not been established and existing regulations were not written with LLMs in mind.
We know OpenAI knows this because they acknowledge the challenge elsewhere. In a post published on April 5th, titled “Our Approach to AI Safety,” OpenAI writes:
While some of our training data includes personal information that is available on the public internet, we want our models to learn about the world, not private individuals. So we work to remove personal information from the training dataset where feasible, fine-tune models to reject requests for personal information of private individuals, and respond to requests from individuals to delete their personal information from our systems. These steps minimize the possibility that our models might generate responses that include the personal information of private individuals.
Here they acknowledge that personally identifiable information (PII) exists in their training dataset and that they aren’t able to entirely comply with correction or deletion requests. Removal “where feasible” and steps that “minimize the possibility” that models “might generate responses that include personal information” (emphasis mine) is not ideal! That these acknowledgments exist in a blog post and not their Privacy Policy is even worse.
It’s hard to not read the above without seeing the very careful yet imprecise language as an artifact of a key tension here: it is obvious that training data is governed by data regulations but it is not obvious that the LLM models themselves are governed by the same regulations.
Certainly, LLM models are not 1-to-1 mappings of their training datasets. But if not, what are they? In one sense, they could be considered derived abstractions of the training data. In another sense, they are distillations of the training data. It doesn’t help that AI boosters market them as the latter when championing them but retreat to the former when defending them.
We can see this tension on display elsewhere in OpenAI’s “Our Approach to AI Safety” post:
Our large language models are trained on a broad corpus of text that includes publicly available content, licensed content, and content generated by human reviewers. We don’t use data for selling our services, advertising, or building profiles of people—we use data to make our models more helpful for people. ChatGPT, for instance, improves by further training on the conversations people have with it.
Sure, OpenAI doesn’t directly use their training data for “selling”, “advertising”, or “building profiles of people.” But according to their Terms of Use they 100% allow companies using APIs powered by GPT to do exactly these use cases. The Terms of Use even list specific, additional standards OpenAI users need to meet if they plan on processing personal data.
Reading the “Approach to AI Safety” post and the Terms of Use we are left to conclude that OpenAI does not view the actions of its models as utilization of their training data.
Finally, Jonathan Turley might argue that the act of training an LLM is “building profiles of people.” An LLM doesn’t know who Jonathan Turley is; it is not a database in the usual sense. But it does have parameters linking his name (of the tokens of his name) to contexts and tokens that are presented as knowledge.
We can see what OpenAI is doing about the problem of erroneous responses in the above. In their communications and documents they minimize privacy issues or simply never mention them.
I am sympathetic. As Steward Brand once said, “If you want to know where the future is being made, look for where language is being invented and lawyers are congregating.” I believe AI is reconfiguring the future (though I hate the term ‘AI’ and think it especially hurts in contexts like this.) OpenAI has been leading the field and setting the pace.
By being aggressive with ChatGPT’s launch, and making it available to all, they’re reaping the benefits of constant feedback. Each conversation held with ChatGPT pushes them out further. This is an entirely new interface and they’re gaining experience while everybody else just tries to launch. The Reciprocal Data Application is a design with network effects, which OpenAI accrues every day they’re live and at the forefront. It’s an enviable position.
In exchange for this lead, they become the target of criticism and concern. But they must lean into the tough conversations, not cede them to be hashed out and written without them. To start, they need to invest in their communication (and not more AGI handwringing, for christ sake) because false accusations against Turley are nothing compared to the fraud that will bubble up shortly. Even if bad actors use LLaMA, they’re going to catch flack.
How OpenAI is Addressing Privacy
- Their Privacy Policy ignores the existence of personal identifiable information (PII) in their training data.
- Their own blog post seem to acknowledge their inability to totally remove PII from their training data and their model output.
- The same blog post says they don't use training data for advertising or profiling, but do not prohibit these use cases in their Terms of Use.
- Rather then highlighting and discussing the differences between training data and models, and openly discussing the regulatory questions, OpenAI seems to deliverately avoid this tension.
How Can We Do Better?
To foster this industry and respect the people whose data is being used to build these models, all LLM owners should consider the following steps:
- Sponsor and invest in projects focusing on data governance and auditing capabilities for models, so we might modify them directly rather than simply adding corrective training.
- Be completely transparent regarding the training data used in these models. Don’t merely list categories of data, go further. Perhaps even make the metadata catalogs public and searchable.
- Work on defining standard metrics for quantifying the significance and surface area of output errors, and associated standards for how they should be corrected.
- Always disclose AI as AI and present it as fallible. More “artificial,” less “intelligence.”
- Collaboratively establish where and how AI can or should be used in specific venues. Should AI be used to grant warrants? Select tenants? Price insurance? Triage healthcare? University admissions?
Collaboration is key here. Right now OpenAI is asking us to take them at their word and trust them without any established history. Outside organizations – including companies, industry groups, non-profits, think tanks, and government agencies – are already starting to kick off their own, separate conversations. Just today, the US Commerce Department invited public comments to inform policy recommendations. These individual entities are all trying to figure this out, separately. As the current leader, OpenAI has an opportunity to help bring these together into productive collaborations.
But if AI companies cede these conversations by avoiding them, their future will be written by reactions to bad news. OpenAI and others need to invest in the boring stuff, have the hard conversations, to foster a world-changing technology. Otherwise, they risk arresting AI’s potential.