Does the Bitter Lesson Have Limits?
Recently, “the bitter lesson” is having a moment. Coined in an essay by Rich Sutton, the bitter lesson is that, “general methods that leverage computation are ultimately the most effective, and by a large margin.” Why is the lesson bitter? Sutton writes:
The bitter lesson is based on the historical observations that 1) AI researchers have often tried to build knowledge into their agents, 2) this always helps in the short term, and is personally satisfying to the researcher, but 3) in the long run it plateaus and even inhibits further progress, and 4) breakthrough progress eventually arrives by an opposing approach based on scaling computation by search and learning. The eventual success is tinged with bitterness, and often incompletely digested, because it is success over a favored, human-centric approach.
Sutton walks through how the fields of computer chess, computer go, speech recognition, and computer vision have all experienced the bitter lesson.
Lately, people have been citing the bitter lesson a lot.
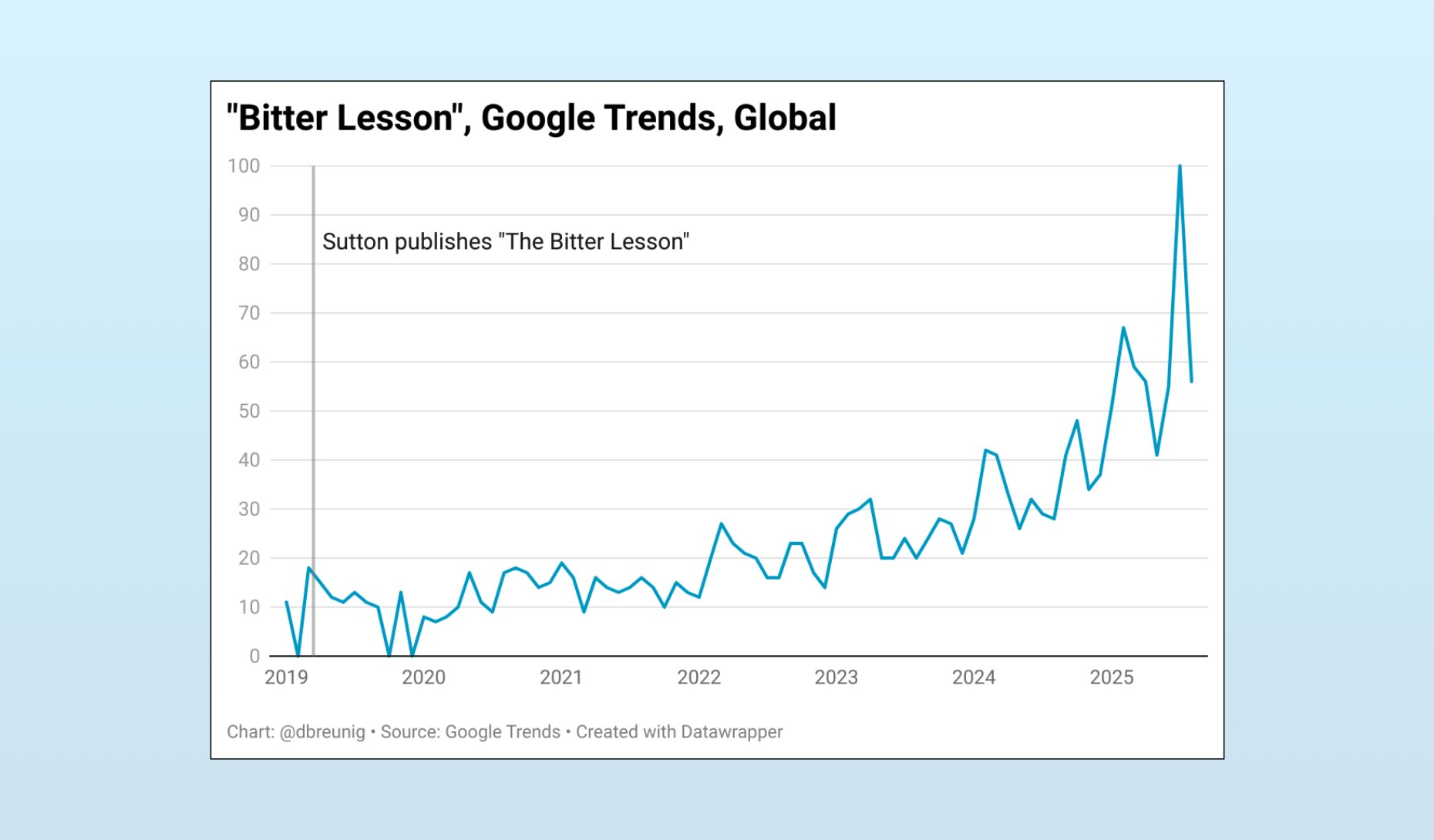
A Blow to the Human Ego
The first time I read “The Bitter Lesson”, I thought of Donna Haraway, one of my professors at UCSC. During a seminar on the history of science, she presented her list of the four major blows to the human ego (which I previously wrote about):
- The Copernican Revolution, which allowed us to realize we weren’t the center of the universe.
- Darwinian thought, which allowed us to realize we weren’t separate from animals.
- Freud’s ideas of the unconscious, which allowed us to realize that we weren’t in full control of our selves.
- Cyborgs, robots, and automatons, which allowed us to realize that non-humans could do the work of humans.
These concepts undermined humans’ imagined central position in the universe.
The bitter lesson slots in naturally here; really a sub-point of cyborgs, a topic which Haraway has been exploring for decades. Within this framework, it’s easy to believe! My instinctual belief reminds me of an exchange from a 2010 RadioLab segment with Neil deGrasse Tyson:
ROBERT KRULWICH: Is it your working bias that if I came to you with a new discovery in which we were less important, or a discovery which proposed that we were more important, that you would guess that my scientific discovery that said we are less important is more likely to be right?
NEIL DEGRASSE TYSON: No doubt about it. That’s correct. Now you call that a bias, but I don’t. I call that track record.
Bitter Skepticism
Surprisingly, the bitter lesson landed on my LinkedIn feed this week. Among the emoji-laden bulleted lists and grindset slop was a new Ethan Mollick piece, “The Bitter Lesson versus The Garbage Can”. In it, Mollick contrasts the step-by-step way businesses are building agents with the reality of business processes:
One thing you learn studying (or working in) organizations is that they are all actually a bit of a mess. In fact, one classic organizational theory is actually called the Garbage Can Model. This views organizations as chaotic “garbage cans” where problems, solutions, and decision-makers are dumped in together, and decisions often happen when these elements collide randomly, rather than through a fully rational process. Of course, it is easy to take this view too far - organizations do have structures, decision-makers, and processes that actually matter. It is just that these structures often evolved and were negotiated among people, rather than being carefully designed and well-recorded.
The Garbage Can represents a world where unwritten rules, bespoke knowledge, and complex and undocumented processes are critical. It is this situation that makes AI adoption in organizations difficult, because even though 43% of American workers have used AI at work, they are mostly doing it in informal ways, solving their own work problems. Scaling AI across the enterprise is hard because traditional automation requires clear rules and defined processes; the very things Garbage Can organizations lack.
The bitter lesson is about to be rediscovered, Mollick suggests. “If AI agents can train on outputs alone, any organization that can define quality and provide enough examples might achieve similar results, whether they understand their own processes or not,” he writes. Org charts and workflows are UX for us humans, unneeded by our agents.
But while I found myself quickly accepting the original bitter lesson essay, Mollick’s essay triggered my inner skeptic. Two practical issues immediately arose:
The bitter lesson is dependent on high-quality data.
Data has an embedded perspective. It is not objective. Further, data is reductive, a shadow of the information it represents. And many things resist being reduced to data points1. Without sufficient data, the bitter lesson cannot be learned.
When Mollick writes, “any organization that can define quality and provide enough examples might achieve similar results,” I immediately focus on the word “can”. Most organizations I’ve encountered have an incredibly hard time defining their objectives firmly and clearly, if they’re able to at all.
Already, companies rely on goal-setting metrics or rubrics like OKRs to attempt to measure that which resists measurement. These can be helpful, but their reductive nature leads to gaming2. Any metrics organizations use to optimize agents with likely be argued over, squishy, and inadequate.
Unlike the workplace, the fields Sutton cites as having met the bitter lesson are ones where the objective is easy to quantify. Victory in go and chess is clear, speech can be directly matched to written text, and most subjects in images can be easily annotated. It’s okay if you find a way to game the system to win a chess game; the rules are air tight.
Further, these fields can be easily represented with data – which is necessary for any general program that needs to learn how to achieve the quantifiable goal. Even if a company can give a clear, firm definition of quality, it still has to figure out how to measure all the interactions involved in producing this output. Otherwise, the program has no ideas what levers if can pull.
If we wish to teach agent-builders the bitter lesson, we need to get better at defining outputs concretely that are resistant to reward hacking (even if they’re not perfect, as we explored yesterday) and figure out how to represent “Garbage Can” organizations with data.
Adding compute is often not practical nor optimal.
Speaking of chess, to illustrate his point, Mollick used both Manus and ChatGPT Agent Mode to create charts documenting the performance of human and computer chess play over time. Here’s ChatGPT’s:
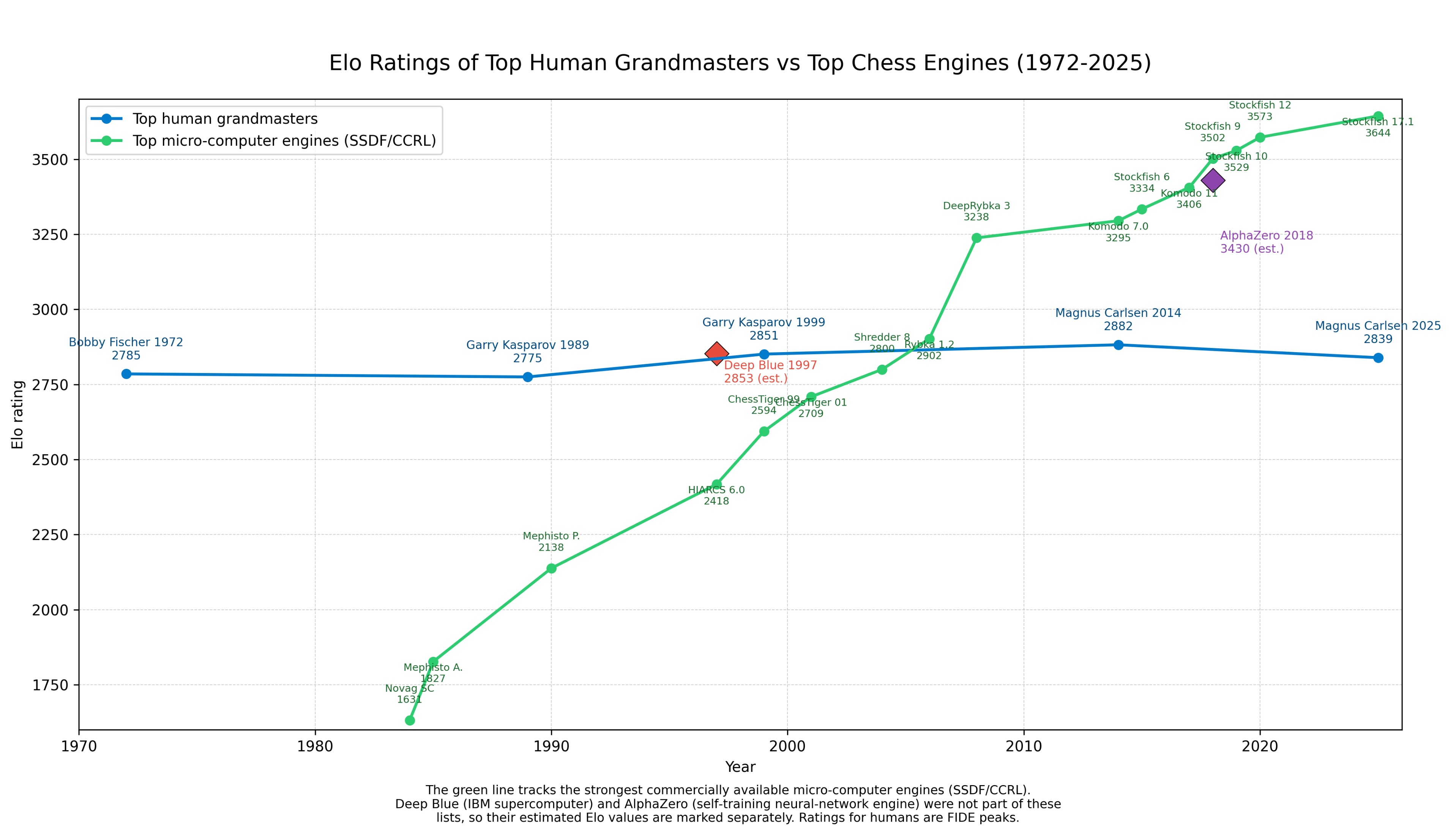
If you’re a chess nerd, you might catch how this plot undermines the bitter lesson: Stockfish, the top performing program since 2020 is not an example of a, “general method that leverages computation.”
Stockfish always had clever search algorithms, but in 2019, its ability to grind out billions of positions didn’t matter because its understanding of each position was kneecapped by human creators. To fix this, the Stockfish team heisted Leela’s deep learning techniques and trained a model hundreds of times smaller than the top Leela model.
After they trained their tiny model, they threw it into their search pipeline, and Stockfish crushed Leela overnight. The Stockfish team utterly rejected scaling laws. They went backward and made a smaller model. But, because their search algorithm was more efficient, took better advantage of hardware, and saw further, they won.
Leela is a deep learning model that, “started with no intrinsic chess-specific knowledge other than the basic rules of the game.” It learned by playing chess, at an absurd scale, until it was the best in the world. A true example of the bitter lesson.
Then Stockfish adopted a small, purpose-built search model inside its conventional chess program. Today, Stockfish remains unbeaten – and can run on your iPhone. By not embracing compute as the primary lever, the Stockfish team not only delivered quality, but delivered something everyone can use, often.
We’re starting to see hints that this pattern might be coming for our best AI benchmarks. ARC-AGI-1, a highly-respected reasoning benchmark, saw its first breakout high score from OpenAI’s o3, last December. This score supported the compute component of the bitter lesson: OpenAI reportedly spent ~$30,000 per task to achieve this milestone. Since this score, ARC has added a “cost per task” metric to their leaderboard, and made efficiency a requirement for their grand prize.
But 3 weeks ago, Sapient published a “Hierarchical Reasoning Model” (HRM), that achieves a 40.3 score on ARC-AGI-1 with only 27 million parameters – besting large models like o3-mini-high and Claude 3.7. (As a reminder, LLM model parameter counts are measured in the billions.) HRM achieves this feat3 with a handful of new techniques, but also each model is trained for only a specific task: the model that scored highly on ARC was trained on 1,000 ARC problems. It’s not built for general use.
A model like HRM could likely run on your phone, just like Stockfish. These aren’t general purpose programs, and they’re not excelling with copious compute. Further, Stockfish is incredibly practical! It can be run basically anywhere (which is actually a growing problem in the online chess scene…) While the bitter lesson did demonstrate new mechanisms for search humans wouldn’t have anticipated, wrapping those in human-knowledge-based rules proves both more performant and practical.
The bitter lesson is an incredibly well written essay. And the argument it makes is compelling because of its simplicity.
But like any rule of thumb, it’s imperfect when it meets the real world. I embrace the idea that general methods that leverage computation will lead us to new ideas and techniques. For many domains, once we understand these mechanisms we can apply them in focused, efficient applications.
And of course – this is entirely dependent on our ability to represent our challenges as data. We can easily model chess and annotate images, but modeling workplace dynamics is much harder.
For those building agents and other AI-powered applications today, it’s good to keep in mind the bitter lesson. Consider where the model might eat your stack, but don’t be afraid to thoughtfully apply custom, human-crafted logic or embrace non-general models to get the job done. And remember: compute is a constraint. Don’t let the bitter lesson stand in the way of actually running your tool. Slightly less accuracy at a fraction of the cost is often the best way.
-
This reminds me of another Haraway quote: “When you freeze a variable you choose to ignore something.” ↩
-
When an ex-Googler first explained OKRs to me, he made sure to note: “The great thing about OKRs is that you usually set them at the end of the first quarter, so be sure to list things you’ve already accomplished this year.” ↩
-
A few people have replicated Sapient’s results on a Sudoku benchmark (another test they demonstrated), but we have yet to see verification for their ARC scores. Though the code is available ↩