Will the Model Eat Your Stack?
The haunting question facing every AI product team: what can you build today that won’t be subsumed by tomorrow’s model?
A good chunk of the first wave of AI-powered products got crushed by this dynamic. They invested significant efforts to build, tune, and test prompts against their specific domain. At the time (circa ChatGPT 3.5), models were powerful but picky. Endlessly tweaking prompts in your pet domain was worthwhile and enabled brand new applications.
But then the GPT-4 level models arrived and nailed many of these challenges with one casual prompt.
On last week’s episode of Hard Fork, Google DeepMind lead Demis Hassabis detailed this challenge while discussing AI-powered product development:
One of the challenges of this space is that the underlying tech is moving unbelievably fast. That’s quite different even from the other big revolutionary techs – internet and mobile. At some point you’d get some stabilization of the tech stack so then the focus can be on product or exploiting that tech stack.
What we’ve got here, which I think is very unusual but also quite exciting from a researcher perspective, is that the tech stack is evolving incredibly fast… So I think that makes it uniquely challenging on the product side, not just for us, at Google and Deep Mind, but for startups… anyone really. For any company, small and large, what do you bet on right now when that could be 100% better in a year? You’ve got this interesting thing where you need fairly deeply technical product people – designers and managers – in order to sort of intercept where the technology is in maybe in a year.
Startups, at least, have an advantage over larger companies like Google in that they can ship products in less than a year (thanks, AI-assisted coding!), allowing them to build on the current state of available models.
The timeline they do need to worry about is what we’ll call the “Subsumption Window”: the time between a product’s launch and the moment when a future model can replicate the product’s core functionality, out of the box.
This is a weird tension because building the product gets easier as the models improve.
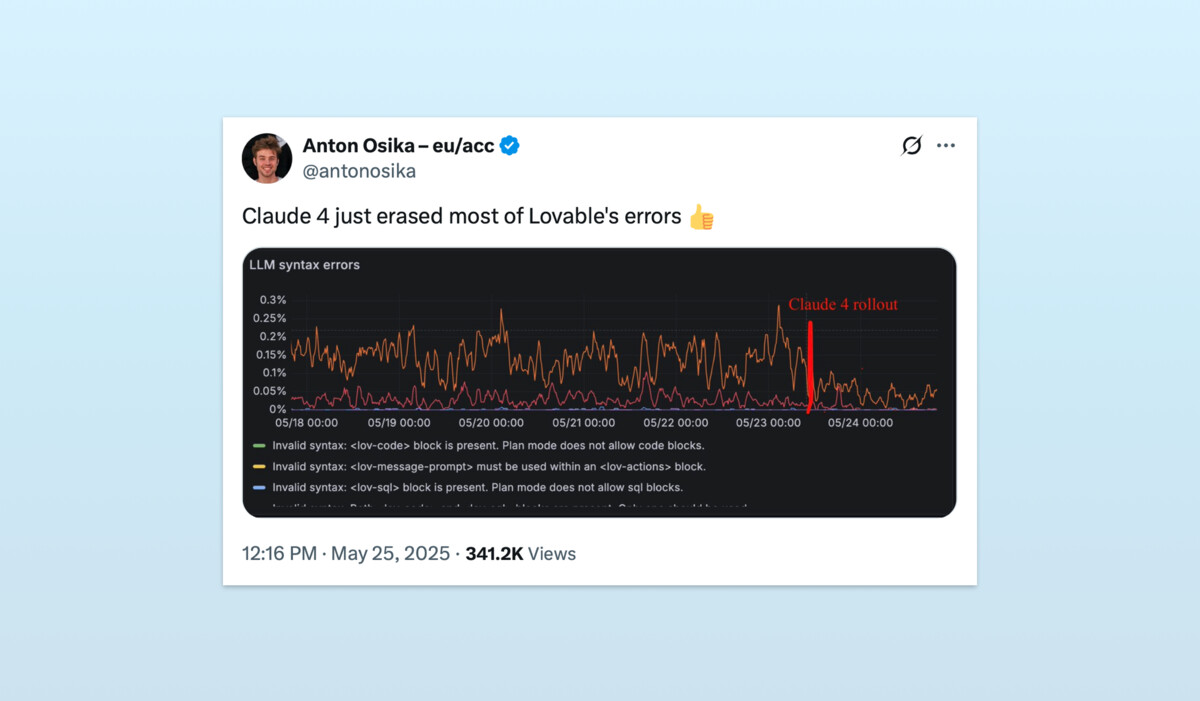
Lovable, an AI-powered app-building tool, saw “most” of its LLM errors wiped out by Anthropic’s new Claude 4. Which is great for them, but also for their competitors.
At the moment, I think the best approach is two-fold.
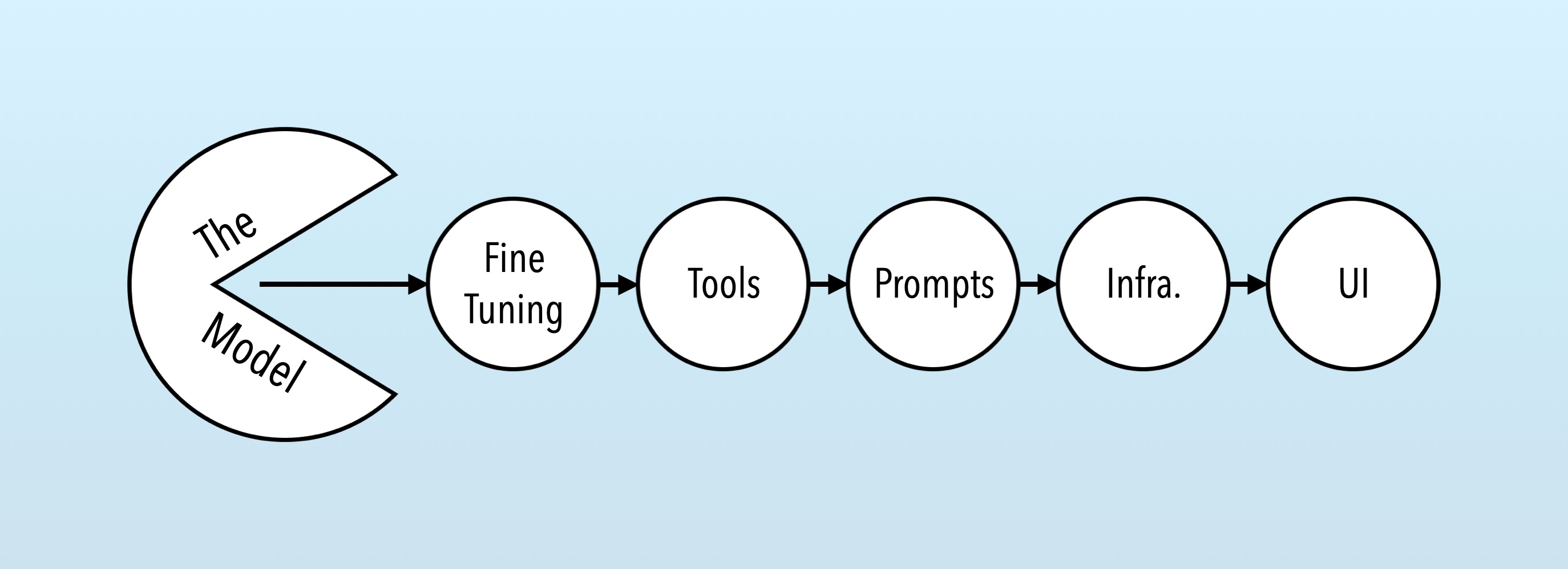
First, consider your whole stack around the model – the fine-tuning, tools, prompts, infrastructure, data, UI, etc. – and focus on one or two components that are more resistant to subsumption by the model. UI and data are the usual front runners, but there are plenty of problems where out-of-the-box models either fail or are much too slow. In these cases, you can bet on longer subsumption windows and start fine-tuning or prompting (but even then: data is king).
Second, once you’re in a market and have found traction, take stock of the current state of AI and reassess your subsumption window. If the models are eating your stack, start work on the next hard challenge and begin establishing a new window.