Learnings from a No-Code Library: Keeping the Spec Driven Development Triangle in Sync
The following is a write up of a talk I delivered at MLOps Community’s “Coding Agents” conference, on March 3rd. There’s a video version of the talk available on YouTube.
I share what I learned building a no-code library, why spec-driven development is a feedback loop not a straight line, historical parallels for our current moment, and a PoC tool for keeping specs/tests/code in sync.
Finally, we consider what GitHub should look like in the era of coding agents.

I was invited here today to talk about a project I launched — a software library with no code — which got a lot of really interesting feedback. I’m going to tell you the whole story, how I got it wrong, explore a bit of historical context, then propose a path forward.

Last Fall, Opus 4.5 launched and surprised everybody with the quality of the code it was produced and the problems it could solve. Opus 4.5 was good enough that we started to ask some really big questions.
I wondered: if the agents are good enough, why do we need to share code?
Whenever I have a big question like this, one that requires lots of thought, I like to go for a long bike ride. So I did, and while I was riding I came up with the idea to ship a software library with no code.

And so we have whenwords.
Open source, freely licensed. It’s a GitHub repository with a markdown file describing what the library is supposed to do. It’s a library that takes a Unix timestamp and converts it into something human-readable — “about 12 o’clock,” “five hours ago,” things like that.
I also generated about 750 conformance tests in YAML: given this input, I expect this output. And one more file called install.md — a single paragraph you’d paste into the agent of your choice, with all the instructions for building the code. You’d drop in what language you wanted and where to save it.
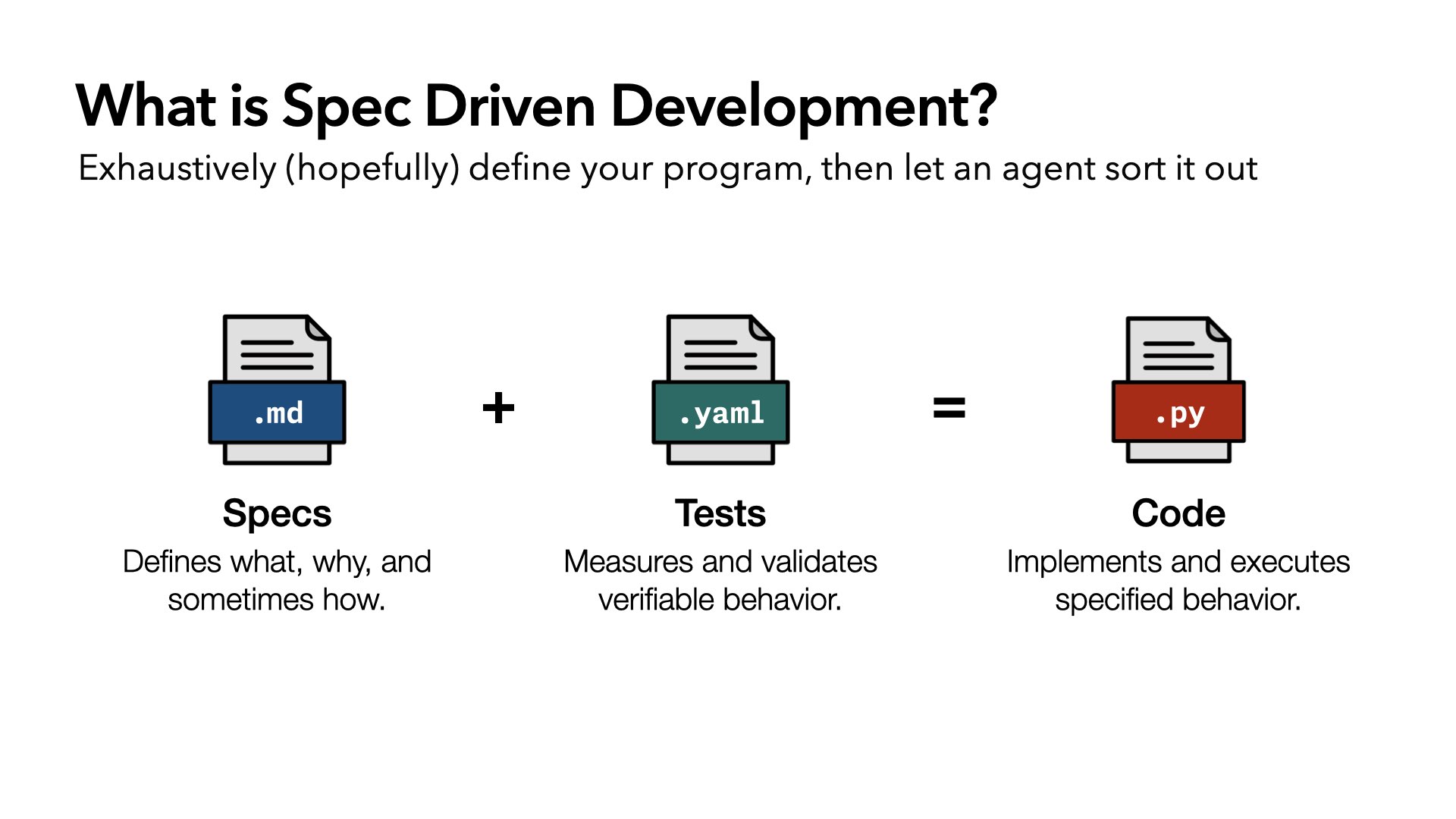
whenwords kicked off a lot of conversation about spec-driven development. It’s something more and more people are thinking about: the idea that if you bring specs, which define the what, why, and sometimes how, and tests, which measure and validate behavior, the code will just flow from that. Give it to an agent, get code out.
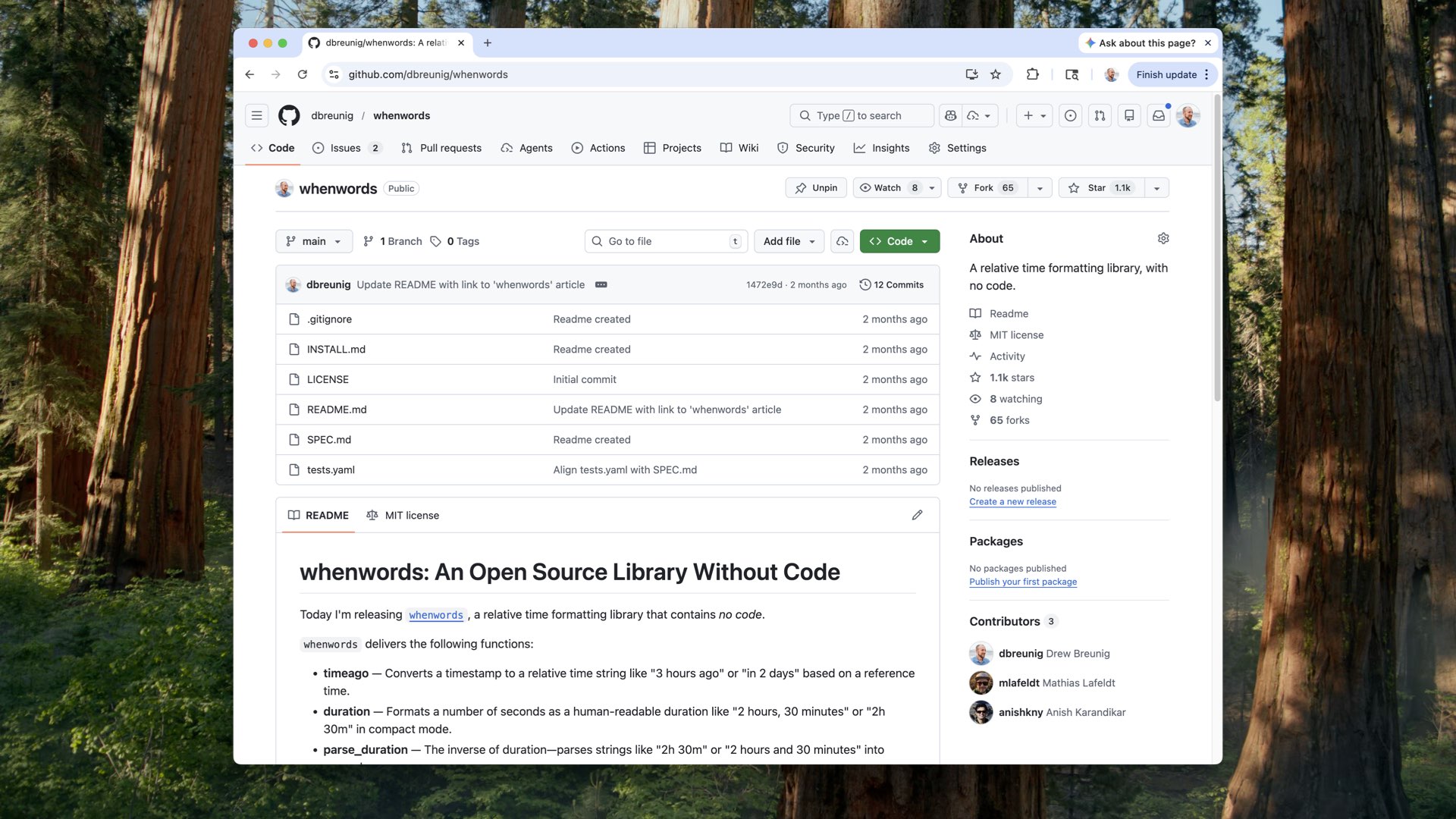
whenwords kind of blew up. Karpathy was a fan. whenwords has over 1,000 stars on Github.
What was even crazier was that I started getting normal GitHub interactions. People submitted issues. They submitted pull requests. And the pull requests were good, things like: “In this test, you’re expecting this result, but that violates the rounding rule you detail in the spec. You need to true these up.”

But I wasn’t the only one with this idea. Larger teams started shipping larger projects. whenwords was a toy; small, constrained, 750 tests. But then:
Vercel released just-bash, a simulated bash environment with an in-memory virtual filesystem, written in TypeScript. Basically re-implementing Bash in TypeScript. They’re running shell scripts against it to verify behavior.
Pydantic released Monty, a Python interpreter written in Rust. Fast, safe, ideal for agent REPLs and code use. Same approach: a pile of Python tests, throw it at the model, make it pass.
Anthropic famously threw 16 Claudes and $20,000 at a spec suite to build a Rust-based C compiler. It didn’t really work. But it was pretty cool.
I couldn’t stop thinking about Spec Driven Development and how far we might push it.

I think there’s a few learnings from this first wave of Spec Driven Development.
Tests and specs aren’t free or easy. All the projects we surveyed used large existing testing libraries from existing projects: the Bash tests, the Python tests, the C tests. Those are the low-hanging fruit. I joked online (and I’m not the first) that pretty soon anyone who wants to protect themselves is going to be like SQLite, where the code is free but you’ve got to pay for the tests. Tests are precious.
Implementation is fast, but not instant. You go fast at first, but none of these projects are complete. just-bash is still being worked on. Monty is missing JSON and other standard libraries. Anthropic’s C compiler stalled out. It gets hard. It’s not perfect and it’s not free.
As complexity grows, structural choices become more important. This was especially clear in the Anthropic project. They got incredibly far, down to 1% of failing tests. But every time they fixed a new bug, it broke something else. Systemic changes required systemic thinking, not just local fixes.
Architectures that allow parallel development are incredibly valuable. What it allows you to do is move fast with multiple agents. And, this is something I haven’t seen explored yet, it allows for open source contribution. Rather than spending $20,000 to build a C compiler, what if you structured it so everyone knows what chunk they can work on? It’s like SETI@home, except I’m not using your engineering expertise. I’m using your Claude Code subscription. Which I think is wild.
But the biggest learning — and the one we’re going to spend the most time on today — is that sometimes the spec and tests aren’t sufficient.
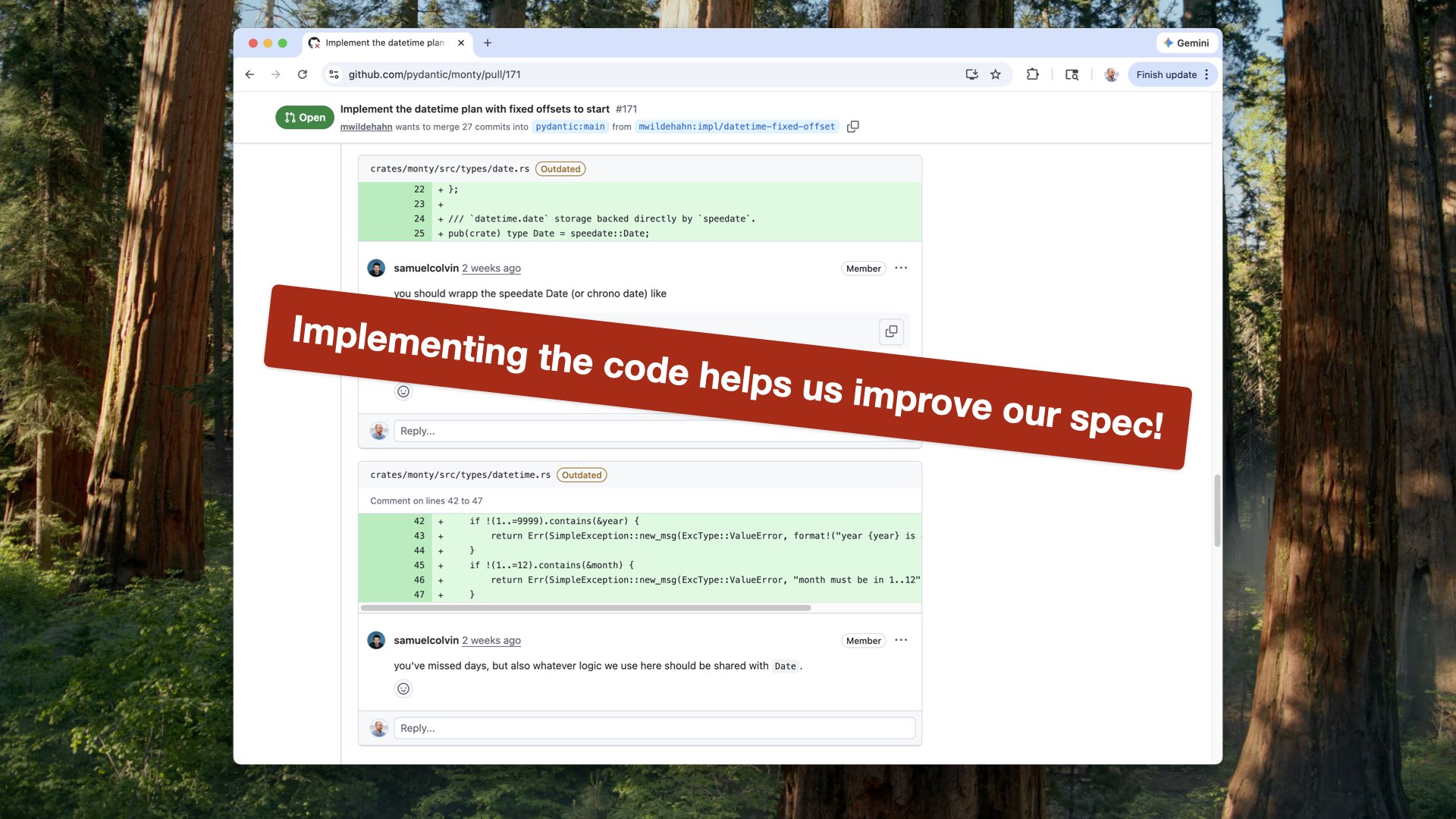
One of my favorite things to do is look at the PRs and issues for all of these libraries. Even with a great spec — “make it run Python perfectly in Rust, here are all the tests, just make them pass” — there are still 20-comment threads about what the right way to implement something is.
Because no spec is perfect. And this is probably my biggest takeaway today:
Implementing the code helps us improve our spec.
Let’s take a digression. We’re at the Computer History Museum, so let’s go back into history. Specifically the history of code and managing code.

One of my favorite jokes about AI development is one I stole from Matt Levine, who writes the finance newsletter Money Stuff. In it, he has a running joke about crypto people speed-running financial history, from first principles, as they attempt to build new financial infrastructure. We are doing that with software engineering and AI coding.
I’m lucky: one of my co-founders, Heather Miller, is a professor at CMU and a programming languages expert. I can call her up, share my theories, and ask: “Heather, tell me this has already been dealt with. Who should I be talking to and what shoud I read?” This time, she said, “Of course it has, Drew,” and introduced me to her office neighbor, Professor Claire Le Goues. Claire then who walked me through the relevant software engineering history, which I’m going to share today because it is incredibly relevant to our current situation.

In 1963, Margaret Hamilton was writing and managing software effort for NASA’s Apollo missions. She coined the term “software engineering” because, running this giant, complicated project that couldn’t have errors in it, she realized: this is engineering. It’s systems design, we have to worry about errors, we have to worry about unexpected inputs like astronauts pushing the wrong button.
And also: we now have enough code that no one person can hold it in their head. Which is a problem, because then you can’t reason about it effectively. And it gets even worse when a team is working on it.
By the way: this is her code. This is what she was managing. This is her VS Code.

And this is her Git.
I’m a dad, which means dad jokes come naturally. So I’m going to retroactively coin Hamilton’s Law: when you can’t see over your code, you can’t oversee your code.
(Sorry.)

After Hamilton dealt with this problem, others realized it was a problem too.
NATO held a conference in Berlin and identified the “Software Crisis”: computer hardware now allowed programs so complex they couldn’t be managed adequately. A single engineer couldn’t hold all the code in their head. If they were going to continue delivering on what software could promise, they needed process.

Dijkstra popularized this in his 1972 Turing Award lecture. He said:
As long as there were no machines, programming was no problem at all. When we had a few weak computers, programming became a mild problem. And now we have gigantic computers, programming has become an equally gigantic problem.
He said this in 1972. Maybe later, walk around the museum we’re in and look at what he was working with then. Then consider what we’re working with today.

So after the Software Crisis emerged, we wandered through the desert of processes, searching for one to borrow. We looked at manufacturing engineering. In 1975, Brooks published The Mythical Man-Month. And finally, Waterfall was adopted as a DoD standard. We learned how to engineer complex software. Progress.

But these things move in cycles. In 2001, we published the Agile Manifesto. Zuckerberg said it’s time to move fast and break things. We embraced Agile, and Agile was finally realized by the cloud and GitHub — which enabled continuous CI/CD and let us offload enough of the error-checking that we didn’t break things too often, even when moving fast.
Which brings us to today.
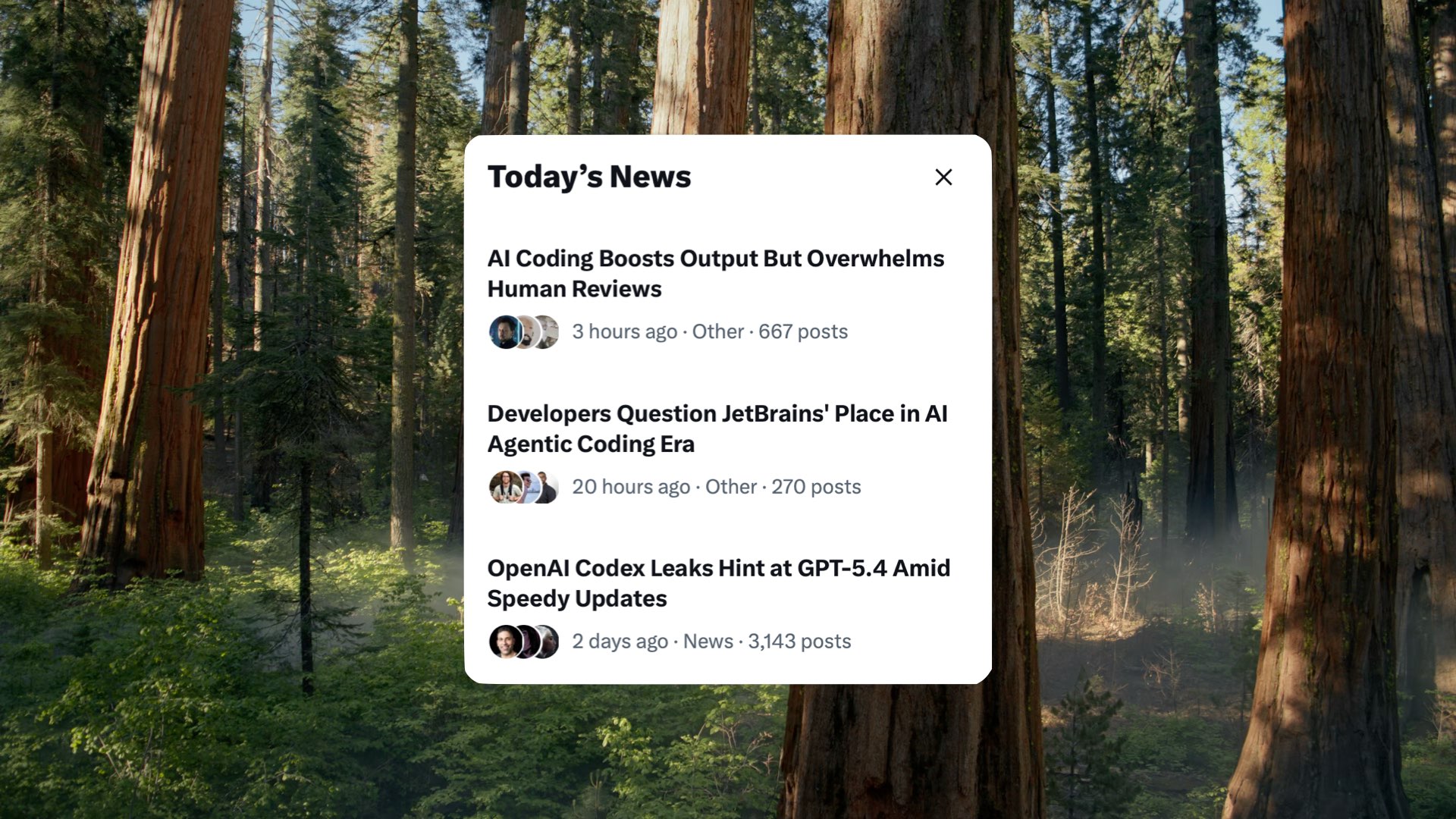
I added this slide right at the last minute, because I logged into Twitter to check something and saw today’s trending news: “AI Coding Boosts Output But Overwhelms Human Reviews.” And it’s paired with that last headline: “OpenAI Codex Leaks Hint at GPT-5.4 Amid Speedy Updates.” So not only is it overwhelming us, it’s accelerating.

So what do we learn from this history rabbit hole?
Being overwhelmed by the volume of code isn’t a new problem. It’s what birthed software engineering.
The initial Software Crisis was our inability to manage complex codebases new computers allowed. Our current Software Crisis is our inability to manage complex codebases new models allow.
Our problem used to be that we couldn’t hold an entire codebase in our head. Now we can’t even read our entire codebase.
Agentic engineering enables waterfall volume at the cadence of agile. And even that undersells it: it’s waterfall times ~two at the cadence of agile times ~seven.
We keep oscillating, historically, between unhindered velocity and managed process. We could use some process right about now. Perhaps AI can help…

I’m not the only one asking this question.
For the last couple of quarters, people have been trying to figure out how to deal with this onslaught of code. The most dramatic example is Gas Town — you’re all familiar with it — an infrastructure for managing a coding process that grew beyond one person’s ability to manage.
But Gas Town just moves the problem. It doesn’t solve it. Steve Yegge even admits this in the Gas Town blog post:
Gas Town is complicated. Not because I wanted it to be, but because I had to keep adding components until it was a self-sustaining machine. And the parts that it now has, well, they look a lot like Kubernetes mated with Temporal and they had a very ugly baby together.

If the process is complex, we’re just moving the problem.
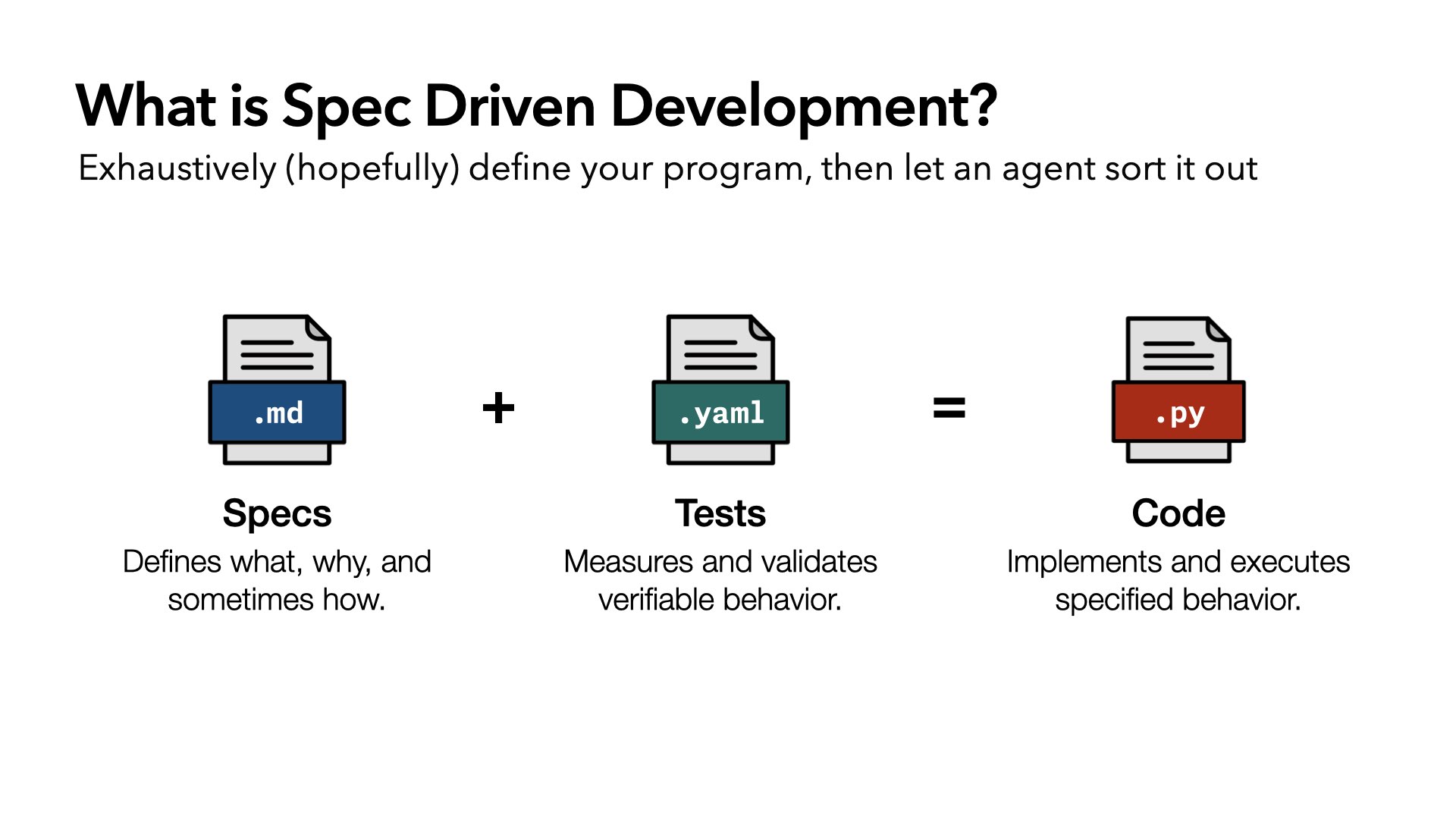
So let’s go back to what we defined spec-driven development to be. This idea that it’s an equation: bring specs, maybe add some tests, add an agent, get code out.
I got this wrong. This is the wrong way to think about it. Because this isn’t a one-way equation. It’s a feedback loop. The act of writing code improves the spec, and it improves the tests. Just like software doesn’t really work until it meets the real world, a spec doesn’t really work until it’s implemented.
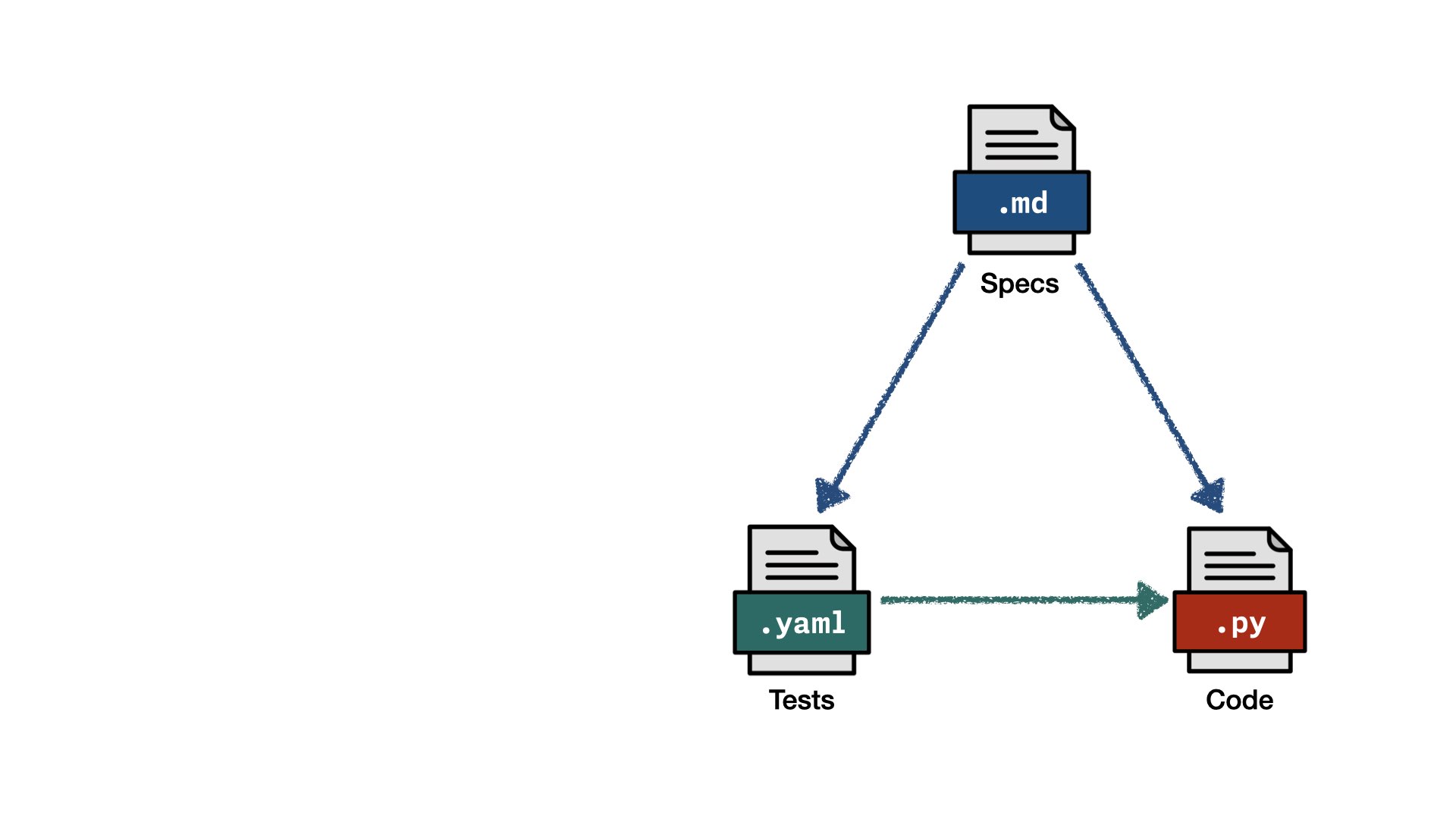
So instead of an equation, I propose a triangle. The spec defines what tests need to be written, and what code needs to be written. Tests validate the code. That’s essentially what we had before, just in a different shape.
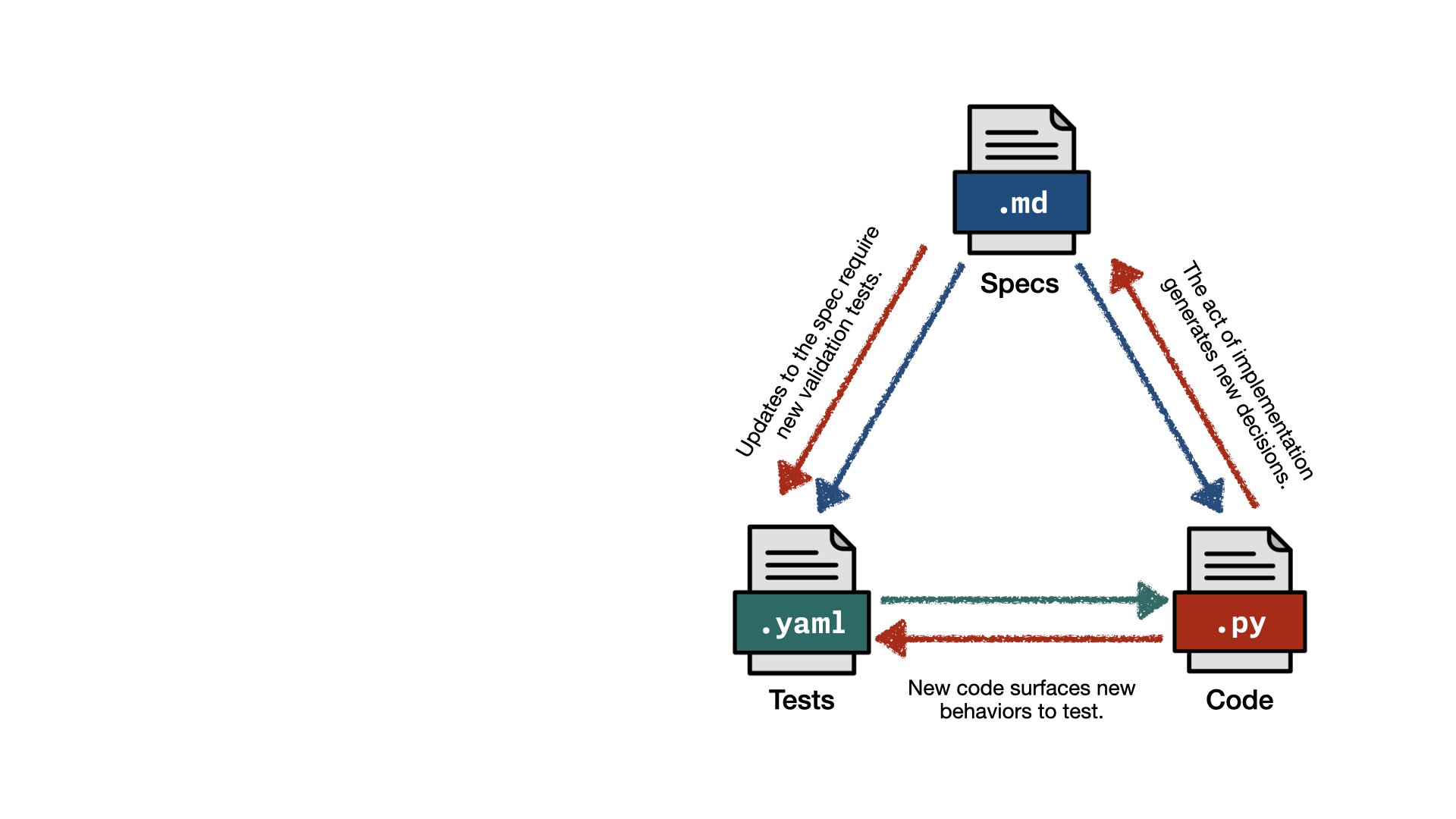
But the act of implementing code generates new decisions. Those decisions inform the spec. And when the spec updates, new tests need to be written. And sometimes it’s not new decisions — it’s just dependencies or subtle choices. New code surfaces new behaviors that need to be tested.
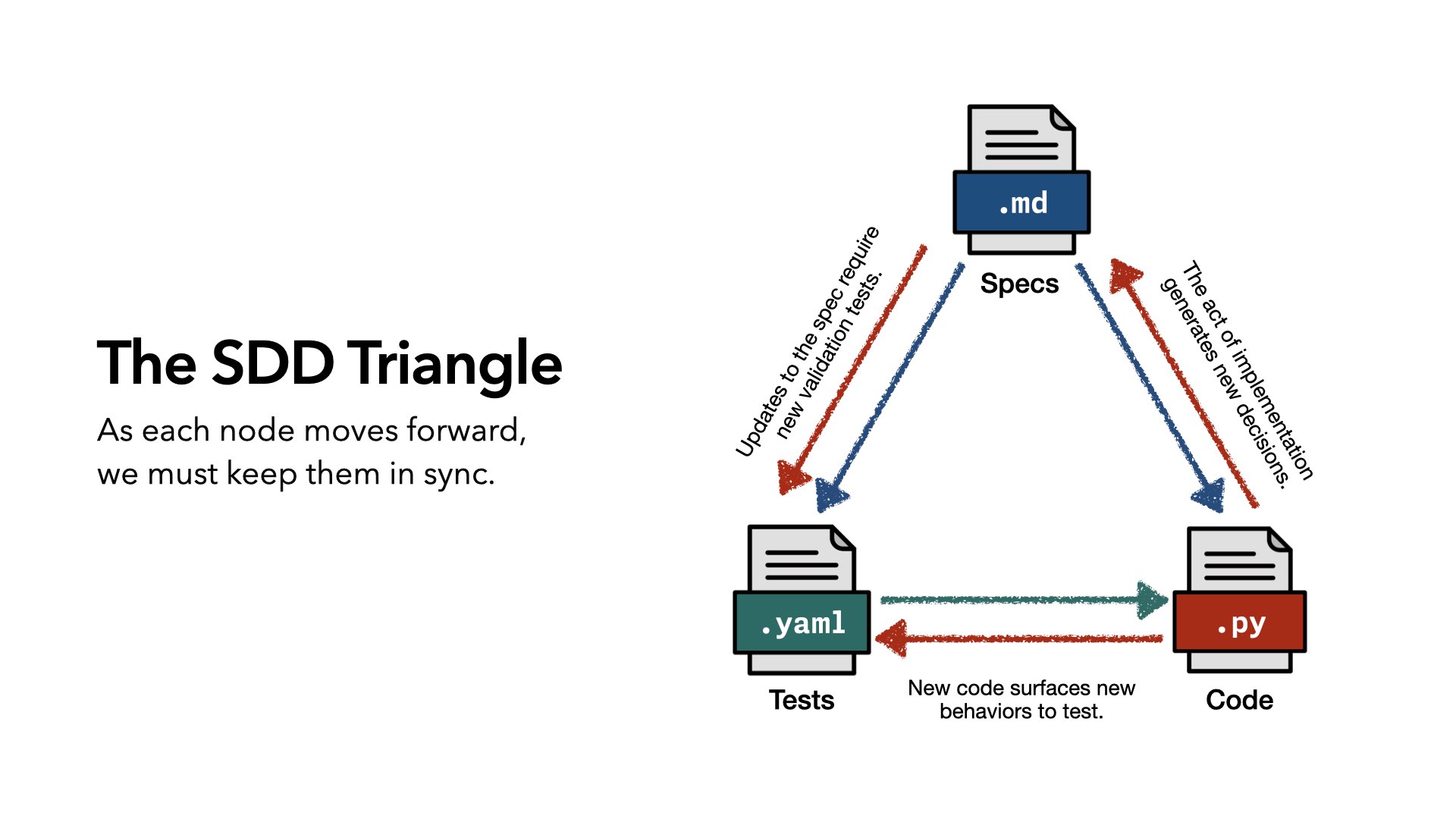
I call this: the Spec-Driven Development Triangle.
As each node moves forward, our job — and our tooling’s job — is to keep those nodes in sync. That’s the job. If we improve the code, we must improve the spec.

But keeping the nodes in sync is hard.
Writing tests is hard. Even before agents, we couldn’t write tests. We don’t like writing tests and we’d prefer not to.
Writing specs is hard. They can never be exhaustive, leave room for interpretation, and are written before the software meets the real world. The spec gets written, it gets implemented, it gets released. Is the spec updated? No.
Specs are written at a different cadence than code, in a different medium. If only we had something that could read natural language.
Updating specs and tests feels like overhead, especially when you’re moving fast. And the entire point of using agents is to move fast. Any system we design has to respect that.
Implementation is messy, and often humans and LLMs take shortcuts. Humans say “I’m not going to implement that right now” or “I’ll come back and fix this.” LLMs certainly do this.
And so regular reconciliation of tests, spec, and code is not part of the process.

But thankfully, there are signals we can work with.
Code changes are tracked by Git, and we can compare them against the spec to find gaps.
Test coverage tools tell us what code is tested — but not whether the tests reflect the spec. It’s not just about covering the code. The tests have to cover the spec.
Updates to the spec — if a product manager logs in and changes something — are also tracked by Git. Is the rest of the system changing with it?
Bug reports and hotfixes that go straight into code or tests need to be captured and rolled into the spec.
And most importantly: implementing the code with an agent generates decisions — from both the humans and the agent. Those decisions exist in the traces. We can look at the traces from our coding agents and find where decisions were made. That’s the signal we need to keep everything in sync.
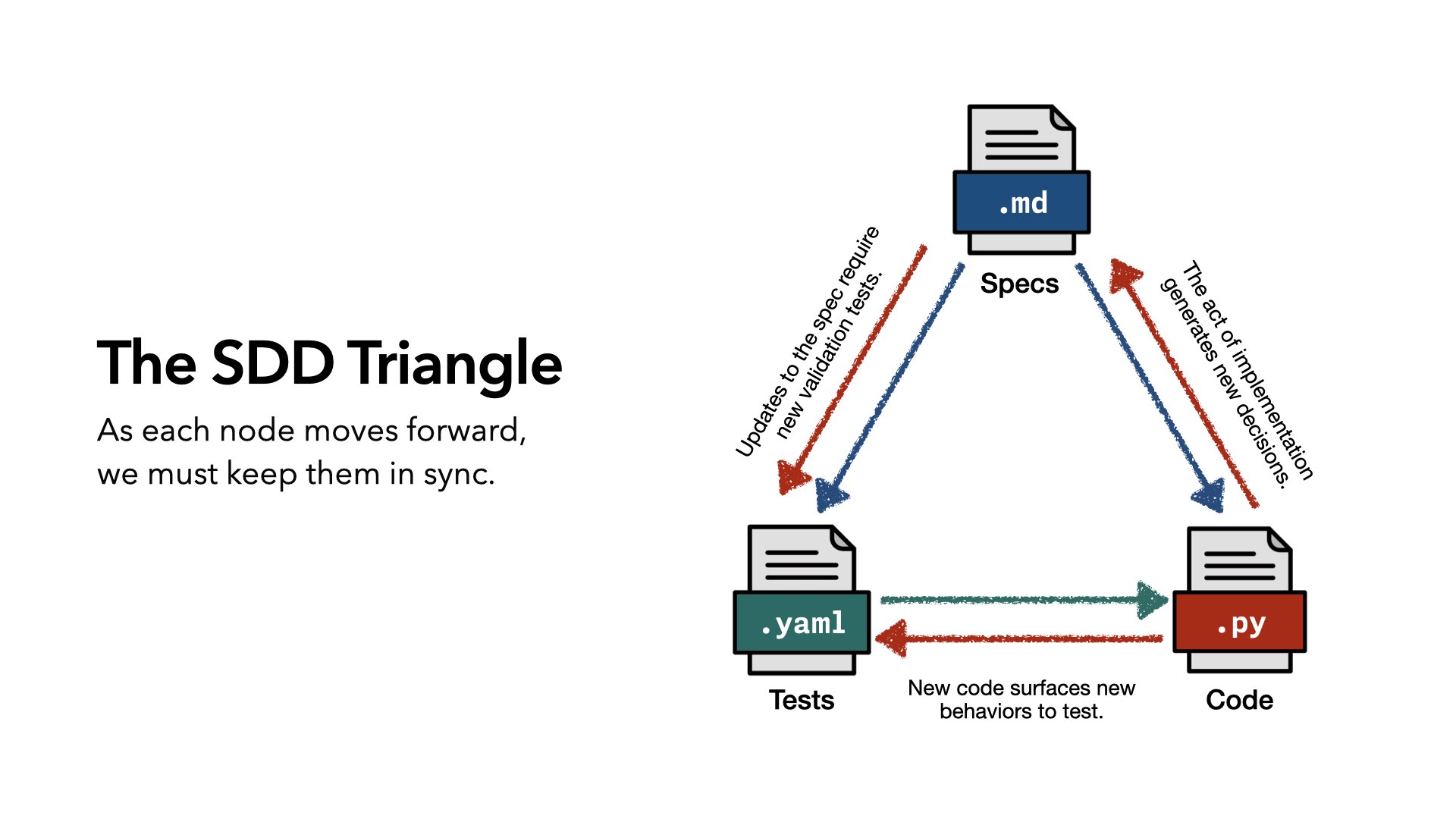
So we have tangible things we can analyze. And a goal to aim towards…
One of the the nice thing about having a thought experiment during the era of great coding agents is that you can just try building it. And as you implement it, you improve it.

This is my tool. I call it Plumb, after a plumb bob, because it keeps things true. A plumb bob hangs from a line and helps a carpenter keep things straight. Even better, they used to be held on tripods, which echoes the triangle.
You can install it right now: pip install plumb-dev or uv add plumb.
It’s not perfect. It’s a proof of concept. A thought experiment as code. But I’ve been using it, and it’s pretty great.

Here’s how Plumb works.
Plumb is a command line tool. Every time you’re working with an agent and you run git commit, it identifies decisions made by evaluating the code diff from the last commit and by reading the agent traces (all the conversations since that last commit). It extracts the decisions, dedupes them, and presents them to you: here are all the decisions you made, do you agree?
Once you’ve approved, it updates the spec to reflect those decisions. It runs sync and reports on coverage gaps between the spec and the tests, and the spec-to-code coverage. Is the code actually reflecting what the spec defines?
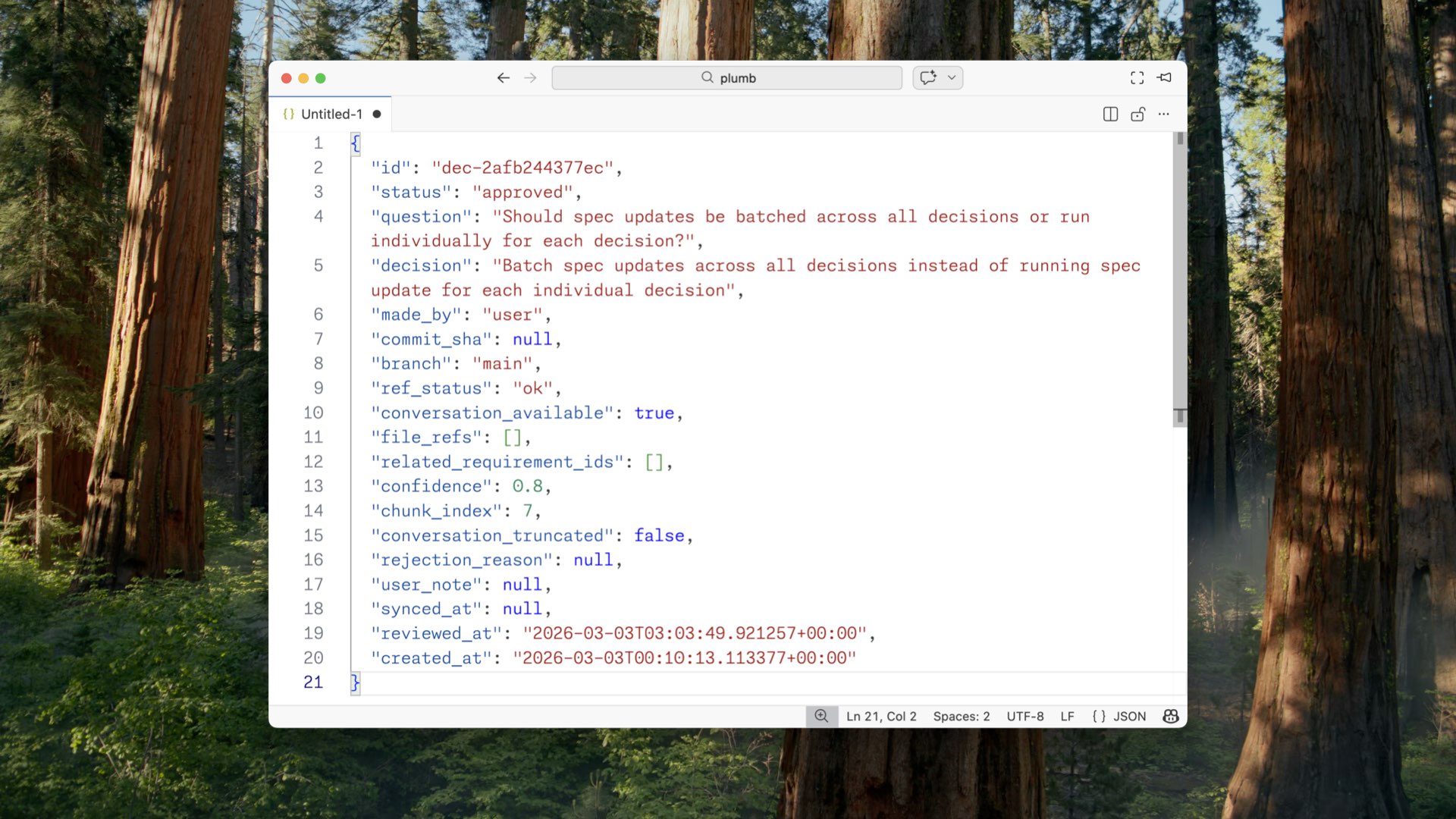
As it does this, it generates files that become artifacts you can track. My favorite is a big JSONL file of decisions.
Here’s one example: “Should spec updates be batched across all decisions, or run individually for each decision?” My decision — batch them. It says it was made by the user, not the LLM. I have blame. And you can see how we can enrich this over time: tie it to code, to branch, to whether it was informed by the conversation, when it was approved, when it was synced. This is not just the code changes. It’s the intent.

To set up Plumb in your project: install it, go to your project directory, run plumb init. It’ll ask you to specify your spec markdown file or folder and show it where your tests are. It creates a .plumbignore to tell it when to skip decision generation — changing the README, for example, doesn’t need to generate decisions. It creates a .plumb folder to store state and config. Very similar to .git.
Most importantly: it adds hooks to Git. When you run git commit, it extracts the decisions. If there are decisions to review, the commit fails. It exits and tells you to review your decisions and approve, reject, or edit them. That’s what makes this work anywhere: command line, CI pipeline, inside your coding environment. It just works. And that’s a hard requirement.
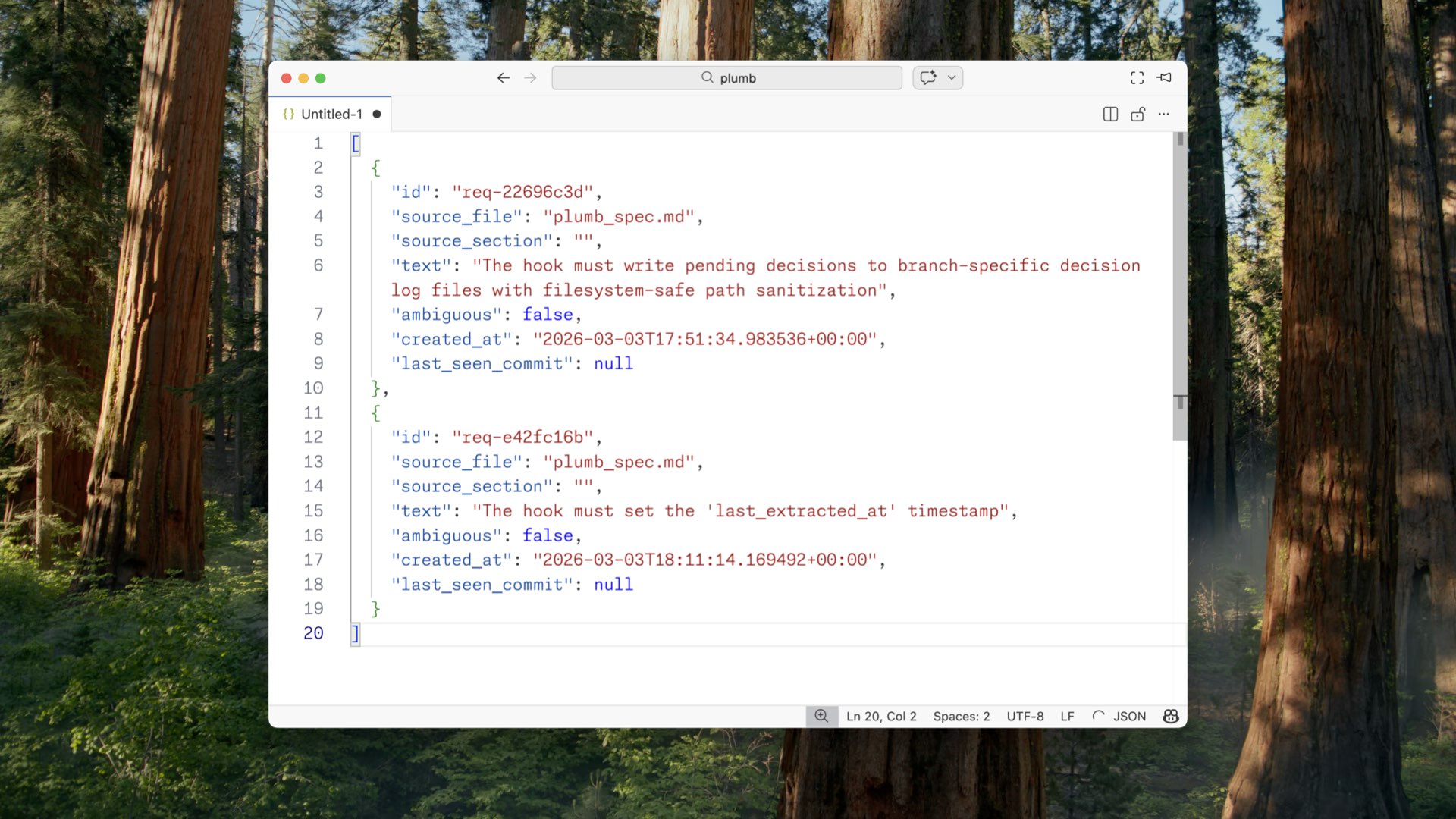
The other thing Plumb generates is a breakdown of your spec into individual requirements — the atomic statements that make up what your spec defines. Ambiguous or not, what source file it came from, eventually linked directly to the code. Right now I use a commenting format to link tests back to the requirement they’re testing, so coverage mapping can show which requirements have tests and how many.

Our aim is link spec to requirements, requirements to code, requirements to tests, decisions to requirements. We’re building a new object graph extending off the code diffs. And eventually — edit the spec, the tests, or the code, pick your poison, and everything else gets brought along.

Now, as you design this, the interesting design choices start to emerge.
Can’t this just be a skill? There are already code review skills, superpowers, things like that. Why not just use those?
I don’t think it can be a skill. Whatever tool we end up using for tracking decisions and intent, it cannot live only inside the agent. It needs to run outside. It needs to handle small commits, triggers, anything…even if you never touch the agent.
A skill is a suggestion. A tool needs to be a checkpoint. That commit-fail mode is essential. Otherwise it gets ignored. We’ve all had this happen with Claude Code.
And the system needs to be canonical. It can’t be optional. Agents wander. Validation needs to be more deterministic. When we can use code, we will. This is a validation and verification step. Fuzzy LLM calls are a last resort.
When we do use LLMs — parsing the spec, extracting decisions — we use DSPy. It lets us structure LLM calls with tight inputs and outputs. It lets us optimize, test, and choose which models to route to. Speed matters enormously here. For decision deduplication, I’m routing to GPT, because it’s faster than anything Anthropic offers for that task. And the whole thing has to be simple enough for the developer to hold in their head.

Of course, there are real limitations.
Plumb only supports pytest. I want it to support any test framework and conformance tests, such as language-agnostic tests like whenwords used.
Decisions might interrupt your flow on long-running tasks. If I make a quick fix and generate five decisions, I have to sit through a review. That needs to be tunable. Maybe you don’t want it to bother you for lightweight decisions, only surface things that are vague or contradict previous decisions. I suspect this is something that will be dictated by the type of project you’re working on.
Deduplication isn’t perfect. Decision identification is fuzzy and will likely need to be project-specific.
Code reversals on decision rejection aren’t working yet. I’d like it so that when you reject a decision the LLM made, it goes back and undoes it. The reason it’s not implemented is that the flow needs to be right: if you reject from the command line, nothing automatic should happen. If you reject from inside the agent, the agent should act on it.
It needs better tools for managing the spec. Mine has grown long and probably should be sharded into sections. Thankfully, this is something an LLM can and should do. Though, we have to be careful when doing it. Perhaps we can perform dry runs, regenerate requirements from the shards, then confirm they match the original spec…
Plumb should be tunable for “just enough” structure. Can I run with --dangerously-approve-all-decisions? Sometimes I want to.
And it’s untested on large projects. Hell, it’s untested in general.

But here’s the fun part: I’ve been testing this by using it to manage the project itself. Using Plumb to build Plumb. And it’s been genuinely useful.
Claude can refer to the spec for implementation understanding without searching the entire codebase. The decision log has proven valuable for answering “why does this code exist?” — I can ask the agent, “is there a decision we made that explains why this is implemented this way?” And it can find it.
It’s code review, but code review where we capture intent. When I hit commit in Claude Code, I get a list of decisions and I step through them. Sometimes I hit one I don’t like and I stop right there. I reject it, go back, redo it. I like that better than pure code review.
It actually spots and controls weird silent LLM behavior. We’ve all let an agent run while we answer email and come back to something insane. Now I get a decision and I can say “don’t do that, let’s roll that back.”
And hacks get documented. I’ve taken shortcuts in this app. Now I know they exist. I can search back for all the shortcuts and then go fix them. The decision log becomes an artifact — not just of code changes, but of intent.
So let’s take this question further. Say Plumb exists and does exactly what I want. How could GitHub be better with this kind of information?
Right now, the main way we interact with code is with Markdown and chat. And GitHub has not changed anything about how we interact with Markdown and text on their site. Could my Markdown diffs have decisions linked to them, so I can see how intent manifests in the code?
I think any version of GitHub that takes the agentic era seriously needs to do four things:
Spec, tests, and code have to be first-class citizens. Code is already. Tests are close — GitHub Actions gets you there. But Markdown is not. Microsoft is probably leaving a lot of inference revenue on the table by not treating it seriously.
Markdown has to be a first-class citizen. This is the gap.
We need to see the linkages. Users need to follow connections between decisions, requirements, code, tests, and spec. Spec-driven development right now is treated as a one-shot thing: write the spec, hit go, you’re done. It’s not. It’s a process. You need to track all of it over time.
Users should be able to ask questions of the system. Not just read it — query it, to get closer to understanding intent. That’s how you actually understand a codebase that’s too large to read.

So here are my takeaways from the journey from whenwords to Plumb.
Code implementation clarifies and communicates intent. I could stop there and walk out of the room. I missed this with whenwords.
The job is to keep specs, code, and tests in sync as they move forward. The system for managing that has to stay simple. If it creates developer mental overhead, it just moves the problem somewhere else.
The act of writing code improves the spec and the tests. Just like software doesn’t truly work until it meets the real world, a spec doesn’t truly work until it’s implemented.
No-code libraries are toys because they are unproven.
Even if you aren’t the one making decisions during implementation, decisions are being made. We should leverage LLMs to extract and structure those decisions.
And finally: we’ve been here before. The answer then was process. The answer now is also process. And just as we leverage cloud compute to enable CI/CD for agile, we should leverage LLMs to build something lightweight enough that we can fit in our heads, doesn’t slow us down, and helps us make sense of our software.

Again: thank you very much to Professor Claire Le Goues, who helpfully walked me through the history of computer science. The history section of this talk is entirely thanks to her. And she has a book coming out, aimed at a wider audience, later this year. Do check it out.