Initial Thoughts on GPT-OSS
OpenAI released its open-weight model, gpt-oss, today. It comes in two sizes, 120B and 20B, the latter of which runs briskly on my Mac Studio. I’m sure I’ll have more impressions as I use it in anger over the next few weeks, but here’s my initial thoughts:
Inference efficiency and speed is improving dramatically lately.
Both gpt-oss and Qwen3-30B-A3B use a mixture-of-experts design that only runs 4B and 3B parameters (respectively, at lest for gpt-oss’ 20B model) when generating tokens. This design is FAST. Go visit OpenRouter and try chatting with gpt-oss. It’ll knock your socks off.
How fast is gpt-oss? Claude Sonnet 4 outputs 55 tokens per second. Running on Groq, gpt-oss 120B hits more than 500 tokens a second. The 20B model? 1,200 tokens a second.
I’m more confident that small models are going to power the bulk of agent functions.
There’s two schools of thought when it comes to agent building.
Some people think you should shove your entire task into a giant model and let it sort it out, with plenty of thinking. It’s expensive, it’s slow, but it (allegedly) requires less upfront work.
Others think you should design your task, in composable steps, where you can measure the accuracy of each step. For most steps, you only need a small model! You don’t need o3 to churn through 3 minutes of tokens to summarize an email body or detect sentiment.
I fall in the latter group. Building compound AI agents and pipelines is cheaper, more accountable, more maintainable… And lends itself to the bulk of the work being done by small, fast models like gpt-oss. And given gpt-oss’ impressive performance, only a small percentage of tasks will end up being routed to giant models. And why would you, when models like gpt-oss are +10x faster?
OpenAI just played a big regulatory card.
Yesterday, the top 5 open models on Artificial Analysis’s leaderboard were from China. Once they evaluate gpt-oss, I’ll be shocked if the US doesn’t have a player in the top two.
It’s astoundingly good, but not perfect.
Based just on today’s usage, gpt-oss is likely my default local model. Its fast and really capable.
But it’s not the best writer. And without a search tool it’s not great on general knowledge benchmarks. Will it use tools as reliably as Kimi or Qwen? We’ll have to see (I’m eagerly awaiting Cline’s report on its agentic coding ability).
But here’s my biggest take-away: for general usage (not agentic coding, for example) the biggest advantage closed, non-local models have are their convenience – not their smarts. They’re always ready, they’re connecting to my documents, and have my common prompts stored. But with a little tuning, LM Studio can be there, too. And perhaps I’ll end up reaching for that first. And that’s crazy to consider.
Oh, one more wonky thing I love about gpt-oss: it has a clean Apache License. Well done!
Update
Artificial Analysis’ updated scores dropped and gpt-oss is the 3rd ranking open model, behind Qwen3 and DeepSeek:
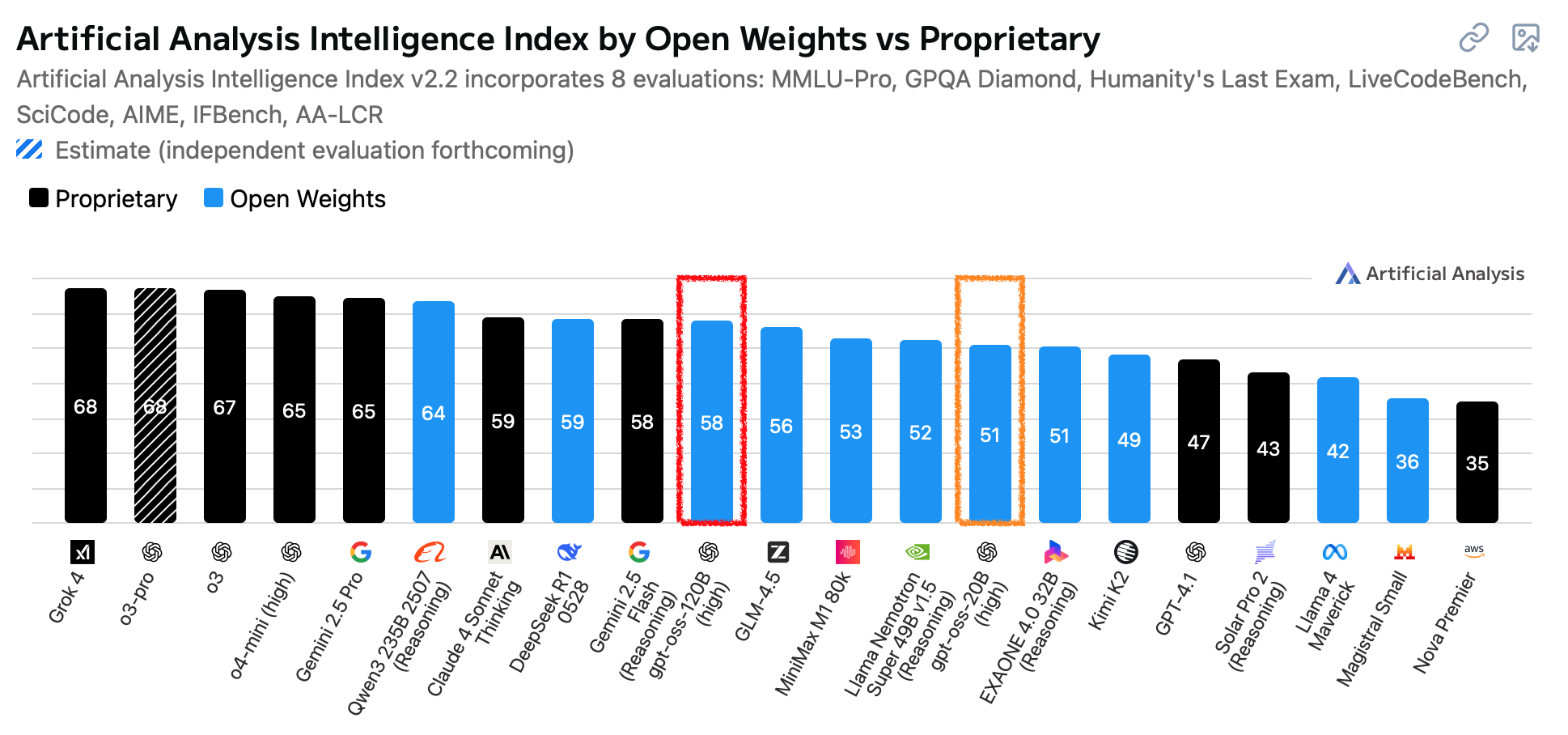
But this is only half the picture. What really impressed me yesterday was gpt-oss’ speed. And this stat sets it apart here:
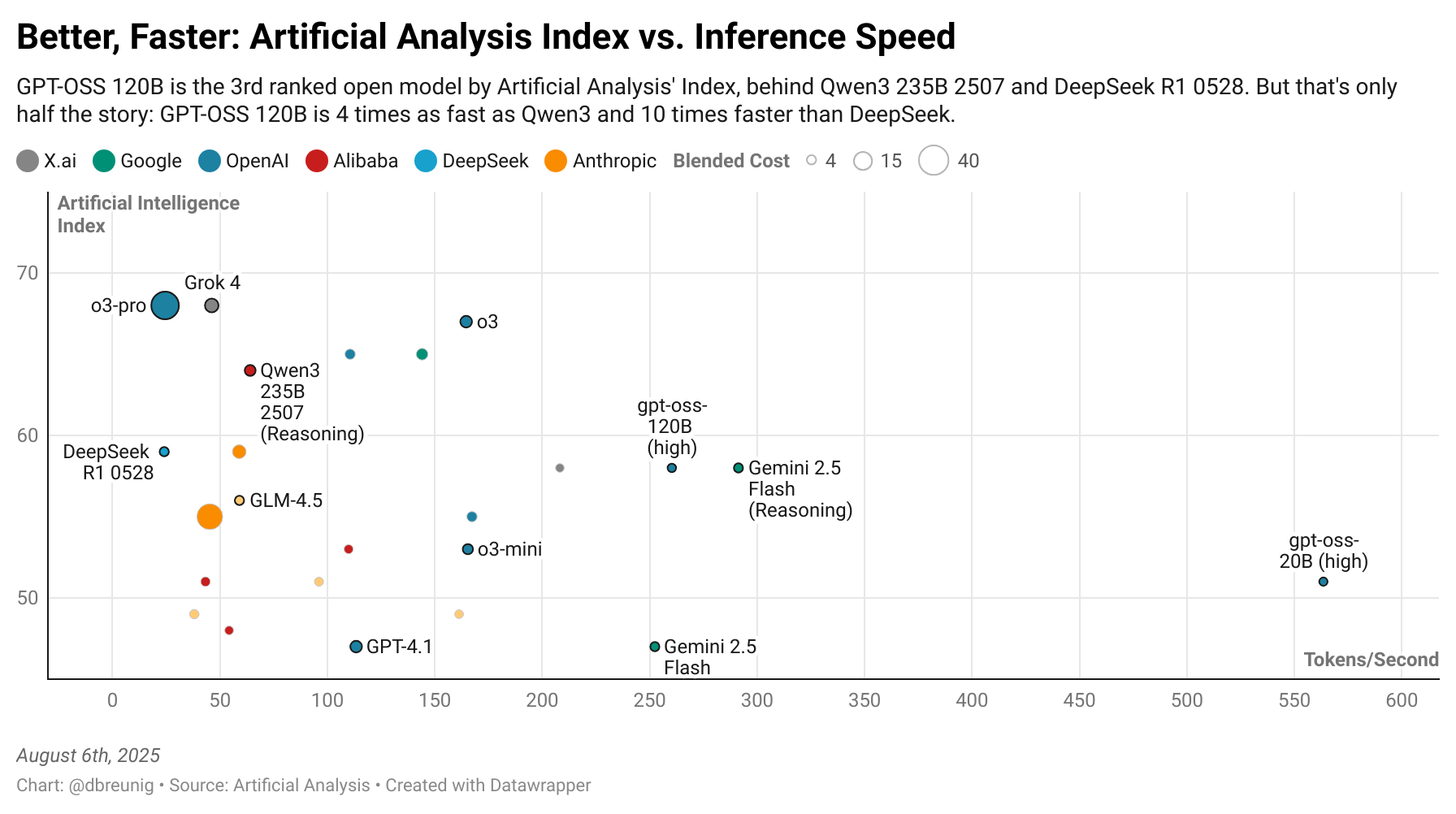
gpt-oss 120B is 4 times as fast as Qwen3 and 10 times faster than DeepSeek.
And look at the 20B model! It’s on an island, by itself, delivering GPT-4.1-beating scores at 5 times the speed.
Sure, standard caveats about thinking time and benchmark gaming apply – but to me this reminds me of how ARC-AGI had to add a cost metric to their benchmarks after o3 demonstrated brute-force reasoning could top the charts. gpt-oss is so fast, while meeting a baseline of quality, it alone is an argument that all benchmarks should report speed of task completion alongside performance scores.