Claude's System Prompt Changes Reveal Anthropic's Priorities
Claude 4’s system prompt is very similar to the 3.7 prompt we analyzed last month. They’re nearly identical, but the changes scattered throughout reveal much about how Anthropic is using system prompts to define their applications (specifically their UX) and how the prompts fit into their development cycle.
Let’s step through the notable changes.
Old Hotfixes Are Gone, New Hotfixes Begin
We theorized that many random instructions, targeting common LLM “gotchas”, were hot-fixes: short instructions to address undesired behavior prior to a more robust fix. Claude 4.0’s system prompt validates this hypothesis - all the 3.7 hot-fixes have been removed. However, if we prompt Claude with one of the “gotchas” (“How many R’s are in Strawberry?”, for example) it doesn’t fall for the trick. The 3.7 hot-fix behaviors are almost certainly being addressed during 4.0’s post-training, through reinforcement learning.
When the new model is trained to avoid “hackneyed imagery” in its poetry and think step-by-step when counting words or letters, there’s no need for a system prompt fix.
Once 4.0’s training is done, new issues will emerge that must be addressed by the system prompt. For example, here’s a brand new instruction in Sonnet 4.0’s system prompt:
Claude never starts its response by saying a question or idea or observation was good, great, fascinating, profound, excellent, or any other positive adjective. It skips the flattery and responds directly.
This hot-fix is clearly inspired by OpenAI’s ‘sychophant-y’ GPT-4o flub. This misstep occurred about a month ago, too late for the Anthropic team to conduct new training targeting this behavior. So into the system prompt it goes!
Search is Now Encouraged
Way back in 2023, it was common for chatbots to flail about when asked about topics that occurred after its cut-off date. Early adopters learned LLMs are frozen in time, but casual users were frequently tripped up by hallucinations and errors when asking about recent news. Perplexity was exceptional for its ability to replace Google for many users, but today that edge is gone.
In 2025, Search is a first-class component of both ChatGPT and Claude. This system prompt shows Anthropic is leaning in to match OpenAI.
Here’s how Claude 3.7 was instructed:
Claude answers from its own extensive knowledge first for most queries. When a query MIGHT benefit from search but it is not extremely obvious, simply OFFER to search instead.
Old Claude asked users for permission to search. New Claude doesn’t hesitate. Here’s the updated instruction:
Claude answers from its own extensive knowledge first for stable information. For time-sensitive topics or when users explicitly need current information, search immediately.
This language is updated throughout the prompt. Search is no longer done only with user approval, it’s encouraged on the first shot if necessary.
This change suggests two changes. First, Anthropic is perhaps more confident in its search tool and how its models employ it. Not only is Claude encouraged to search, but the company has broken out this feature into a dedicated search API. Two, Anthropic is observing users increasingly turning to Claude for search tasks. If I had to guess, it’s the latter of these that’s the main driver for this change, and a strong sign that chatbots are increasingly stealing searches from Google.
Users Want More Types of Structured Documents
Here’s another example of system prompts reflecting the user behaviors Anthropic is observing. In a bulleted list detailing when to use Claude artifacts (the separate window outside the thread Claude populates with longer form content), Anthropic adds a bit of nuance to a use case.
From Claude 3.7’s system prompt, “You must use artifacts for:”
“Structured documents with multiple sections that would benefit from dedicated formatting”
And Claude 4.0’s:
Structured content that users will reference, save, or follow (such as meal plans, workout routines, schedules, study guides, or any organized information meant to be used as a reference).
This is a great example of how Anthropic uses system prompts to evolve its chatbot behavior based on observed usage. System prompts are programming how Claude works, albeit in natural language.
Anthropic Is Dealing With Context Issues
There are a few changes in the prompt that suggest context limit issues are starting to hit users, especially those using Claude for programming:
For code artifacts: Use concise variable names (e.g.,
i,jfor indices,efor event,elfor element) to maximize content within context limits while maintaining readability
As someone with strong opinions about clearly defined variables, this makes me cringe, but I get it. The only disappointment I noticed around the Claude 4 launch was its context limit: only 200,000 tokens compared to Gemini 2.5 Pro’s and ChatGPT 4.1’s 1 million limit. People were disappointed
Anthropic could be limiting context limits for efficiency reasons (while leaning on their excellent token caching) or may just be unable to deliver the results Google and ChatGPT are achieving. However, there have been several recent explorations showing model performance isn’t consistent across longer and longer context lengths. Here’s a plot from a team at DataBricks, from research published last August:
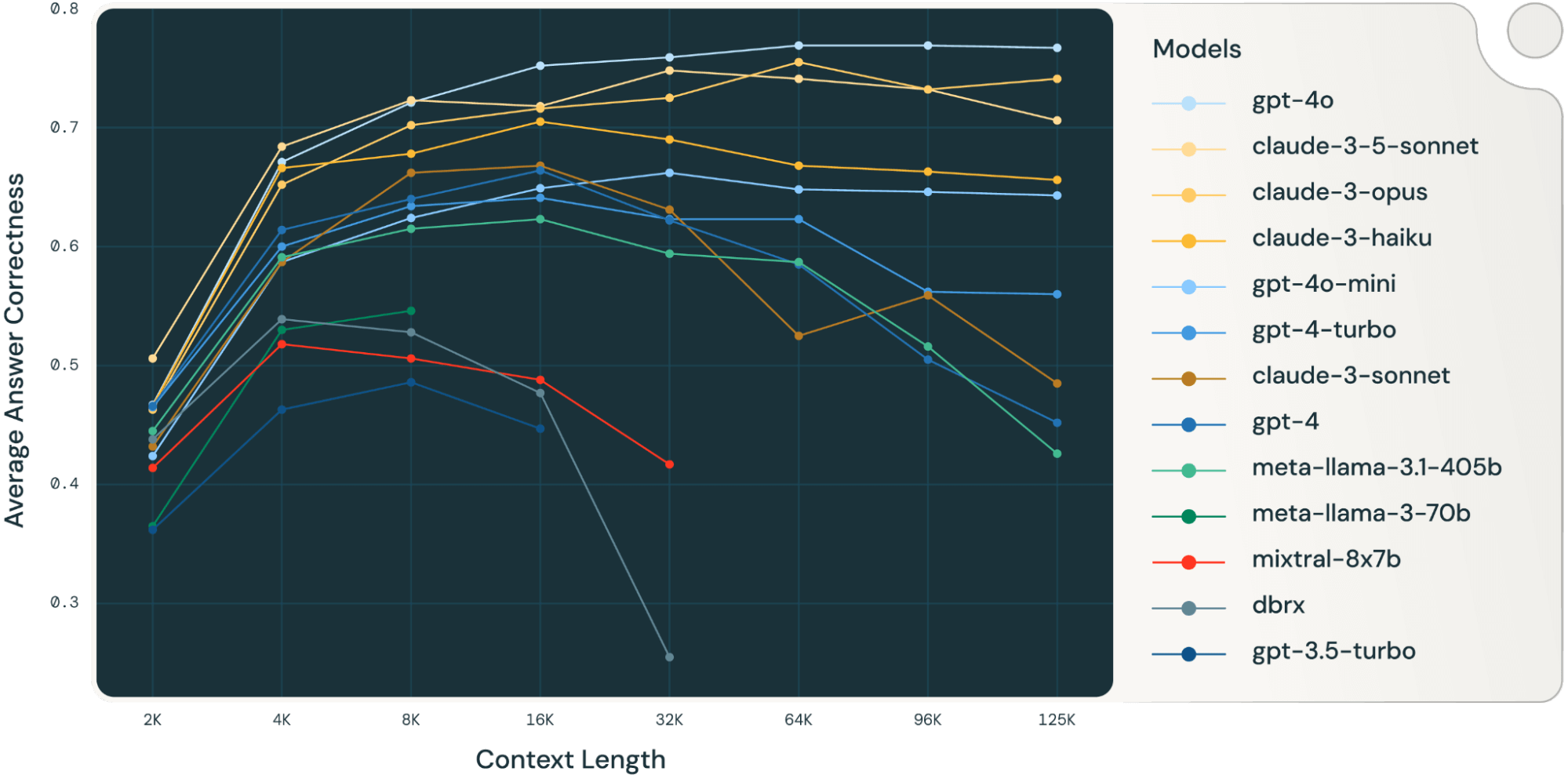
I’ve been in situations where less scrupulous competitors focused on publishing headline figures, even if it led to worse results (for example in the geospatial world, many will tout the total count of all the elements in their dataset, even if many have very low confidence). I’m inclined to believe a bit of that is occurring here, in the hypercompetitive, benchmark-driven AI marketplace.
Either way: I think we’ll see all coding tools build in shortcuts like these to conserve context. Shorter function names, less verbose comments… it’s all on the table.
Cybercrime is a New Guardrail
Claude 3.7 was instructed to not help you build bioweapons or nuclear bombs. Claude 4.0 adds malicious code to this list of no’s:
Claude steers away from malicious or harmful use cases for cyber. Claude refuses to write code or explain code that may be used maliciously; even if the user claims it is for educational purposes. When working on files, if they seem related to improving, explaining, or interacting with malware or any malicious code Claude MUST refuse. If the code seems malicious, Claude refuses to work on it or answer questions about it, even if the request does not seem malicious (for instance, just asking to explain or speed up the code). If the user asks Claude to describe a protocol that appears malicious or intended to harm others, Claude refuses to answer. If Claude encounters any of the above or any other malicious use, Claude does not take any actions and refuses the request.
Understandably, that’s a lot of caveats and conditions. It must be delicate work to refuse this sort of aid while not interfering with general coding assistance.
Reviewing the changes above (and honestly, that’s the bulk of them from 3.7 to 4.0), we get a sense for how system prompts program chatbot applications. When we think about the design of chatbots, we think about the tools and UI that surround and wrap the bare LLM. But in reality, the bulk of the UX is defined here, in the system prompt.
And we get a sense of the development cycle for Claude: a classic user-driven process, where observed behaviors are understood and then addressed. First with system prompt hot-fixes, then with post-training when building the next model.
The ~23,000 tokens in the system prompt – taking up over 11% of the available context window – define the terms and tools that make up Claude, and reveal the priorities at Anthropic.