The Wisdom of Artificial Crowds
Building a Distributed AI Network of Diverse, Emergent Intelligences

A few weeks ago, two papers caused me to reassess my expectations for the future of AI.
Not because they showcased some breakthrough capability or jaw-dropping new technique, but because they pointed to a different path forward — one where progress doesn’t rely solely on ever-larger models but instead on networks of smaller, diverse, and specialized intelligences.
At their core, LLMs are average machines. They predict the next token based on the sum of all the data they’ve been trained on. Much of the time, this is exactly what we want: the consensus answer to a question, derived from an internet’s worth of content.
But sometimes, we don’t want the average. Recently, we discussed how reasoning models “search” as they reason. They’ll nominate and explore multiple, potential solutions to your problem, exploring each before settling on the hopeful ideal.
For searching, we don’t want the average. We want a scattershot of diverse, yet relevant potential paths.
But if diversity is what we’re after during the “search” stage, why should we rely on only one model?
Prior to the emergence of reasoning models, people started experimenting with LLM ensemble techniques: prompting many different models with the same prompt, and then using another model to assemble a final answer from the various outputs. Squint a bit and this looks a bit like the “searching” reasoning models perform, but at the time the main driver was the fact that different models were better at different things.
Initial ensemble techniques never really found traction, likely because the gains in LLM performance and efficiency were so great from 2023 to 2025. Why complicate your pipeline when another model will arrive next week that’s better and cheaper than any of the others in your stable?
But now that we want diversity while reasoning, we should give ensembles another look.
This is not because large reasoning models aren’t capable of coming up with diverse approaches (they’re so big there’s more than enough to draw from) but because smaller models can generate an array of approaches faster for a fraction of the cost.
The price range among LLMs these days is enormous. Taking a look at Simon Willison’s handy LLM pricing page, we can see a four-magnitude difference between the most expensive and cheapest models. For a more practical comparison: OpenAI’s flagship o3 is 10x the cost of GPT-4.1 Nano1.
Small models are also much faster. Sticking with the same OpenAI lineup comparison, GPT-4.1 Nano is over 25 times faster than o3 (~300 tokens per second compared to 11 tokens per second).
Suddenly, a pipeline where we ask a small model the same question 100 times before asking a giant model to synthesize everything looks pretty attractive! We just need something to make that task easy.
A Framework for a Network of Networks
A few weeks back, a team led by researchers from Foundry, Databricks, Stanford, and a smattering of other labs released Ember, a framework for composing tasks like the one above.
Here’s what it looks like:
# Create your pipeline
pipeline = non.build_graph(["100:E:gpt-4.1-nano:0.7", "1:J:o3:0.2"])
# Prompt the pipeline
result = pipeline(query="What causes the northern lights?")
In that first line, we built exactly the pipeline we described above. 100:E:gpt-4.1-nano:0.7 means we want an ensemble of 100 requests to gpt-4.1-nano. 1:J:o3:0.2 means we want the responses from the ensemble judged with one request to o3.
The brevity of Ember is handy, but there’s plenty of less-compact notations available to spec out complex graphs, assigning different jobs to different models, in parallel and sequential structures.
Generating Diversity With High Temperatures
The eagle-eyed among you likely noticed the trailing numbers in our graph definition, the 0.7 and 0.2. These figures set the temperature of our models.
Temperature is a parameter that controls the randomness of an LLM. Setting a low temperature instructs a model to add little to no randomness when generating tokens. Whatever is statistically the most likely token will be returned.
By setting a high temperature, we’re instructing a model to add a little randomness when picking the next token. Most of the time, it’ll pick the first or second most likely token. But sometimes it’ll dip even lower. This sounds like a small tweak, but because a model references all previous tokens when figuring out the next thing to generate, this randomness compounds.
If you’re running a local LLM, you can see this for yourself. (And if you’re not, here’s how you get started) Let’s give the following prompt to Llama 3.2, a 3 billion parameter model:
Reply with one word only. What is the next word in this sequence: My name is
If we set our temperature parameter to 0.0, Llama 3.2 always responds with, “Pete.” Regenerate the prompt again and again – you’ll always get “Pete.”
But if we raise our temperature to 0.7 and generate 10 responses, we get the following:
- Percy
- Patrick
- Pete’s
- Pete
- Pete
- Percy
- John
- Pete’s
- Peterson
- Pete
Now we’re getting some randomness, though we’re bouncing around the most likely next tokens (with P and Pe being the clearly top-ranked). If we dial our temperature up to 2.0, we get “Penny”, “Alexander”, and “Robert” – nicely illustrating the increased randomness.
We can now see why our temperature values were set to 0.7 and 0.2 in our Ember call. For our ensemble of 100 tiny models, we want plenty of randomness – 0.7 – to ensure the responses cover a wide surface area of possibilities. But for our large judge model, we kept our temperature very low – 0.2 – to keep it focused on logically synthesizing a single, representative response.
Generating Diversity With Fine Tuning
The day Ember launched, DataBricks’ AI research team published a blog post titled, “The Power of Fine-Tuning on Your Data: Quick Fixing Bugs with LLMs via Never Ending Learning (NEL).” While reading this piece immediately after Ember’s blog post, a vision for a diverse, distributed AI future snapped into focus.
But first: the blog post.
In the Databricks interface, there are three LLM-powered features: autocomplete, chat, and “Quick Fix.” Quick Fix is exactly what it sounds like: if a bit of code in a cell fails to run, Quick Fix will recommend a correction. The user can reject the change or accept and and run the code.
The Mosaic AI team ran an experiment where they hooked up the Quick Fix feature to GPT-4o and the much smaller Llama 3.1 8b. When backed by Llama 3.1, Quick Fix’s performance was terrible. However, when a code cell was corrected by the user, the team would use this data to train Llama 3.1.
Pretty soon, the Quick Fix trained Llama model was outperforming GPT-4o2:
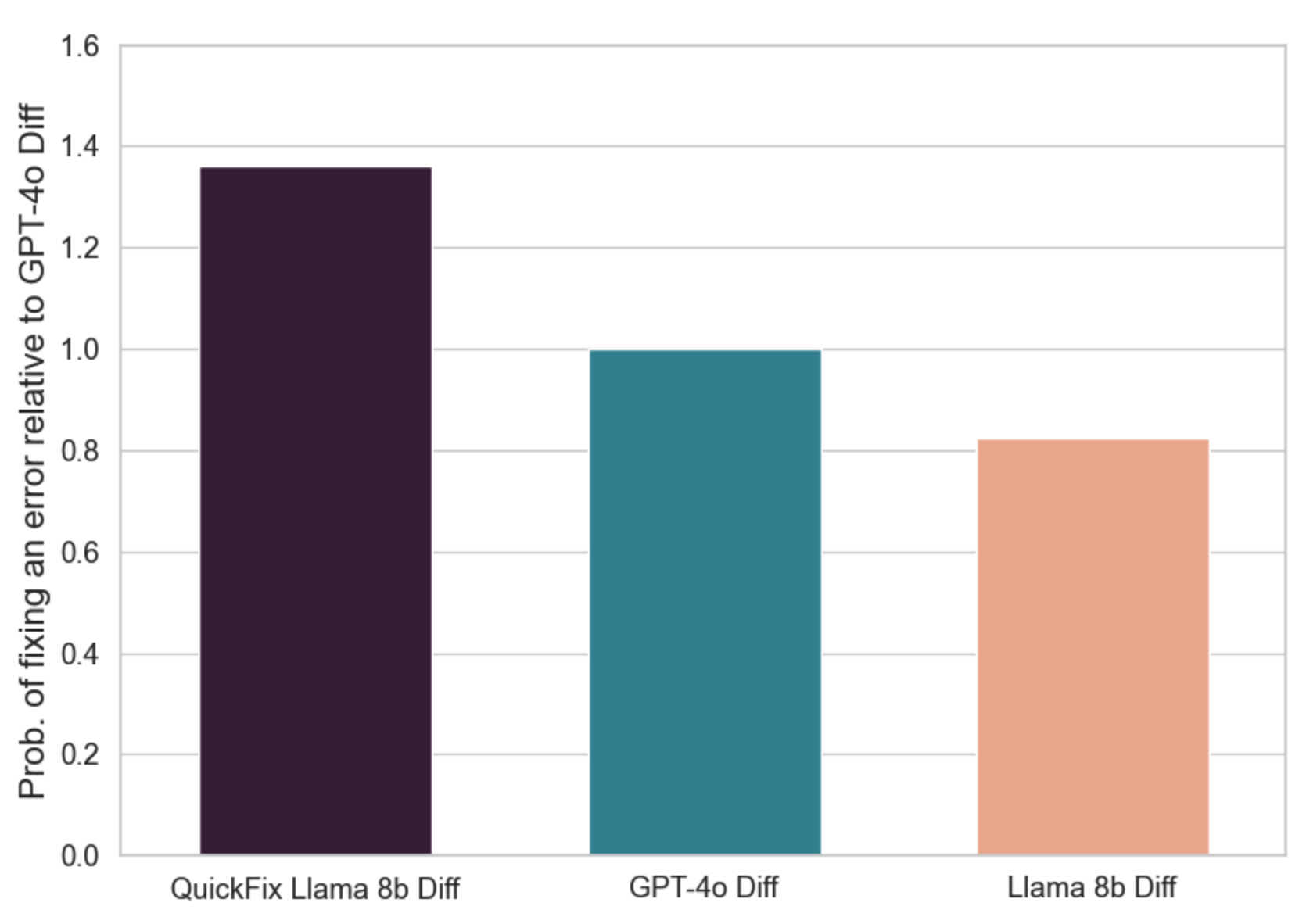
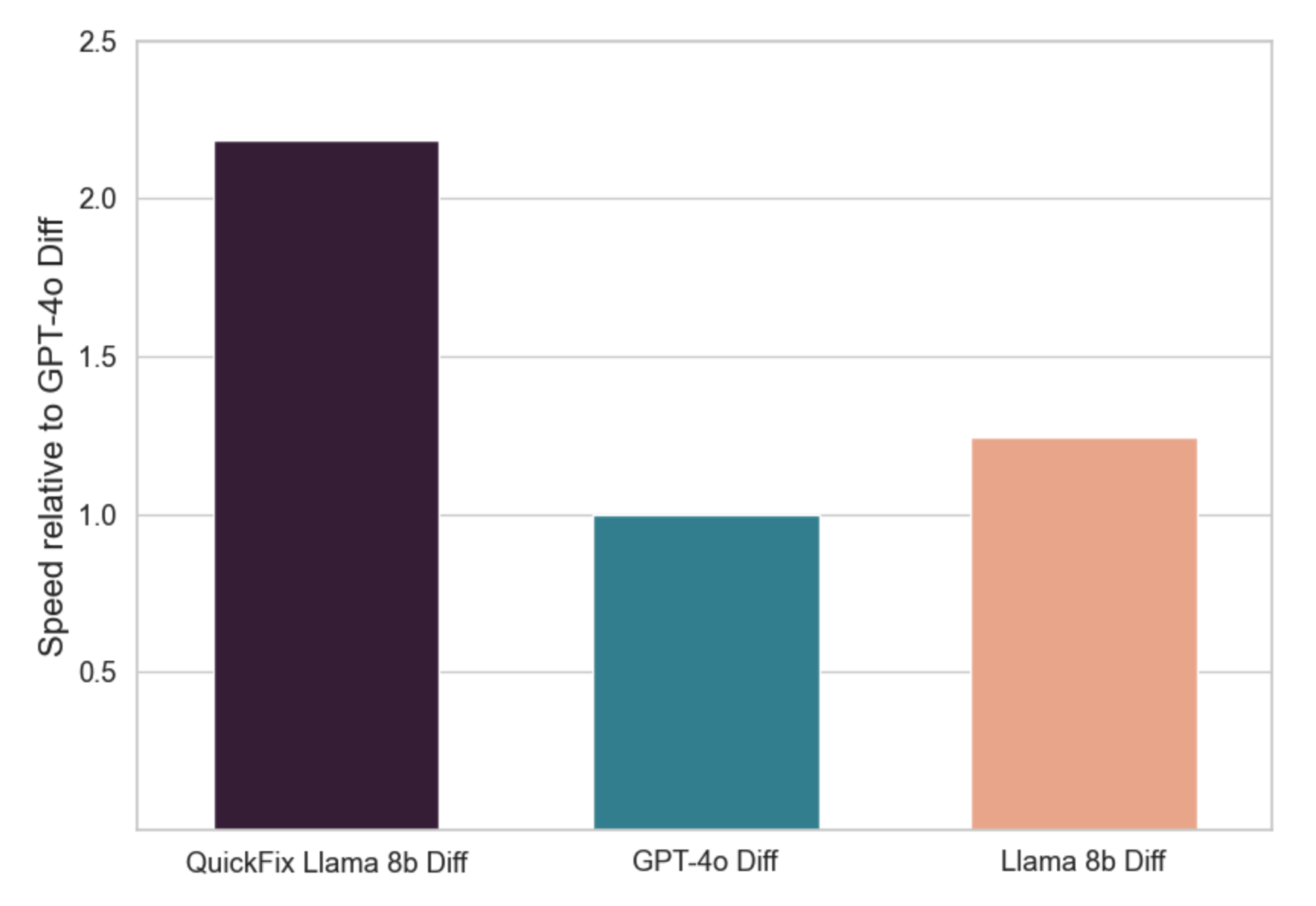
And the tuned Llama performed over twice as fast:
But the real improvement is that the fine-tuned Llama learned the conventions and preferences of the Databricks team. For example, GPT-4o is quick to rewrite code in Python or load libraries you’d prefer not to use (which may not even exist!). This is a common problem for Databricks team members, who often write in SQL. GPT-4o often rewrites an entire cell as Python, loading PySpark and translating SQL lines to formatted strings. (This behavior isn’t limited to GPT-4o; Claude frequently “fixes” my DuckDB scripts by rewriting them as Python scripts using the DuckDB library.)
The Quick Fix trained Llama model doesn’t have this issue: it was trained on corrections written by the Databricks team, through the act of performing their usual work.
The fastest, cheapest, and best model’s skills are localized to the team.
Fast, Cheap, & Diverse
Which brings us back to the topic of diversity.
The Quick Fix fine-tuning pattern – where models are continually trained with corrections written by an individual programmer or team – builds better, diverse models. If this pattern were deployed across many teams and developers, we’d end up with many different yet performant models. Further, these fine-tuned models can be small, fast, cheap, private, and good.
And if these diverse models are remotely accessible, we can connect them together in a network of networks, polling them with tricky coding questions before synthesizing their diverse responses with a judge model.
Many novel applications come to mind, utilizing this pattern:
- A company could have specific product teams maintain their own fine-tuned models, constantly trained by programmers working on that specific domain. The teams get the benefit of a model that doesn’t fight their localized conventions and new team members get a leg-up when starting out. But for big questions, they could poll models from every team, drawing on the diverse approaches of their individual employees.
- Assisted coding apps – like Cursor or Cline – could allow users to actively fine-tune small models, hosted locally, enabling quick, cheap responses that adopt their conventions. Further, these companies could form domain “communities” that each train different models to learn their specific languages or frameworks. Such models could better adhere to a language’s conventions and more quickly adapt to new releases and APIs.
As small models continue to improve and coding assistants continue to evolve, I’m hopeful we’ll see more localized training. A potential peril of dependence on the largest models is a lack of intellectual diversity. We can hack it by training reasoning models to search, tweaking our temperatures, and improving ensemble frameworks. But what local training brings is a diversity of perspectives, which I suspect will be more valuable together than a single, large average machine.
We’ve often talked about how LLMs are improving more quickly in verifiable domains. Because we can evaluate the correctness of code with unit tests and compilers, we can generate as much synthetic coding data as we need. However, as any developer will tell you, just because code compiles doesn’t mean it’s optimal. Passing a unit test doesn’t mean the code is stable, secure, efficient, or readable. While programming is more objective than many fields, anyone who has actually worked with engineers knows there is no shortage of arguments and perspectives. A diversity of perspectives makes everybody’s arguments sharper and results in better decisions, architectures, and code.
Locally tuned small models connected with network-of-networks frameworks could preserve this diversity, enabling better reasoning and synthesis outcomes. The ability to leverage an emergent network of unruly intelligence could become another network effect.
-
During normal use this cost factor will be dramatically higher, as o3’s reasoning produces much longer outputs than the non-reasoning GPT-4.1 Nano. ↩
-
I edited these charts for clarity, removing a bar that goes beyond the scope of this article. If you’re curious, I encourage you to read the entire write up. ↩