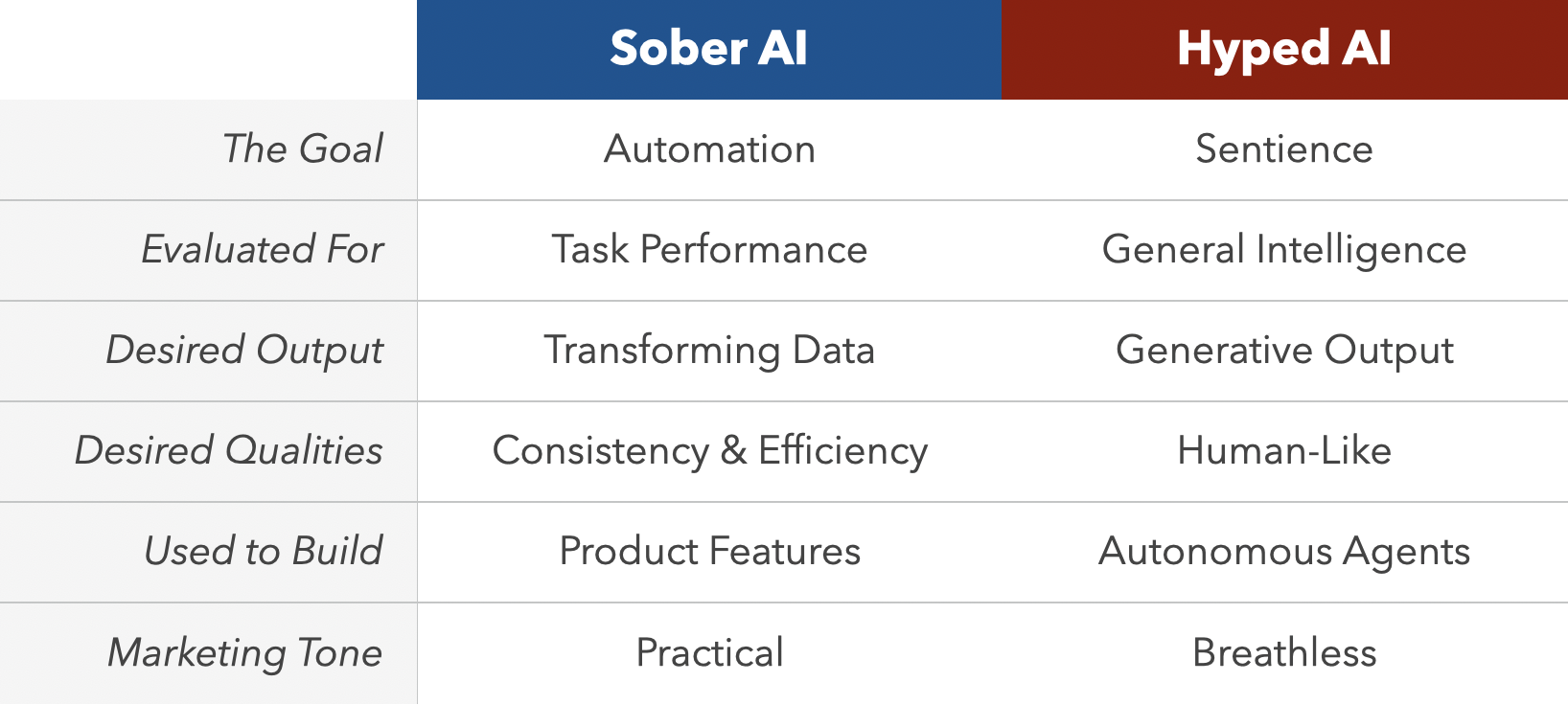
Sober AI is the Norm
The boring pursuit of business intelligence for all
Last month, I wrote a plea for sober AI, lamenting the level of hype from OpenAI, Google, and countless other companies and boosters. “Imagine having products THIS GOOD and still over-selling them.”
But below the hype, there’s incredible, humble work being done. This is the field of Sober AI.
My beliefs were validated at the Databricks Data+AI Summit this week. With hundreds of companies represented and five figures of attendees, there was quite the spectrum of work to discuss. It’s an interesting moment, as the AI field is at a point where best practices are only now starting to settle, workflows are starting to be established, and enough people have been working with LLMs in violence that we’ve learned what does and doesn’t work. The cement’s not dry yet, but we now have an idea of the shape of things.
And Sober AI is the default.
Among the case studies, sessions, and meetings, I was struck by how mundane developing with LLMs actually is.
Despite the shine of AI, working with LLMs looks like data science and data engineering work circa 2019. Most effort is spent acquiring data, cleansing data, preparing data, synthesizing data, staging data, evaluating model results, and debugging. The actual “AI” work – the training, fine-tuning, and prompt engineering – is a small slice of the day to day.
Further, as teams discover that zero- or one-shot prompts to off-the-shelf models are insufficient for most non-toy applications, we’re seeing compound AI systems become the dominant pattern. And in these systems – made up of multiple models and functions – AI looks like just another pipeline component.
Don’t think of LLMs as magic, but as just another function in a pipeline or program.
This ‘just another function’ quality will increase as companies like Databricks, Huggingface, Microsoft, and others continue to build better tooling around LLM fine-tuning, eval, hosting, and more.
If I were a proponent of Hyped AI, I’d rebut the above by noting that all of this is expected. When presented with a wholly new technology, humans initially use it to do the things they already do:
- The first movies were just filmed stage performances. Only after we began to wrap our heads around editing did we begin to create cinema.
- The first cars were motorized horse carriages. Only after reliable roads were built and factory innovations did automobiles become the cars we know today.
- The first personal computers just emulated our desktops – the notepad, calculator, and recycle bin. Only with the rise of networking did we have the tools to realize the communication innovation that is the internet.
When data scientists, engineers, and product managers use LLMs in workflows that look like their existing workflows, perhaps that’s due to a lack of vision.
I think this is likely true. We need new infrastructure, tools, and experience before we can realize the wholly new applications LLMs allow. But in the meantime, the relatively boring applications of Sober AI are so valuable that it’s worth our time and attention.
Take, for example, RAG and generating SQL statements from natural language input. Both use cases received plenty of attention at the Summit this week and with good reason. Both functions enable people to actually use the enterprise data we’ve spent so much time and money making sure they can access. Achieving the reality of delivering business intelligence in response to simple sentences will be a massive step toward turning enterprise data into a true force multiplier.
It’s weird to find ourselves in a place where delivering data-powered intelligence for all sounds like a relatively mundane exercise. But when there’s hype about super-human, sentient artificial intelligence, I suppose even big deals sound boring.