Enterprise Agents Have a Reliability Problem

Enterprise agents struggle to reach production or find adoption due to reliability concerns
Throughout 2025, there’s been a steady drumbeat of reports on the state of AI in the enterprise. On the surface, many appear to disagree. But dig in a little bit, look at how each report was assembled and how they defined their terms and you’ll find a consistent story: adoption of 3rd party AI apps is surging while 1st party development struggles to find success.
If you’re short on time, here’s the tl;dr:
- Off-the-shelf AI tools are widely used and valued within the enterprise. (Wharton/GBK’s AI Adoption Report)
- But internal AI pilots fail to earn adoption. (MIT NANDA’s report)
- Very few enterprise agents make it past the pilot stage into production. (McKinsey’s State of AI)
- To reach production, developers compromise and build simpler agents to achieve reliability. (UC Berkeley’s MAP)
The few custom agents that make it past the gauntlet figure out how to achieve reliability, earn employee trust, and actually find usage. Reliability is the barrier holding back agents, and right now the best way to achieve it is scaling back ambitions.
Let’s start with the notorious MIT NANDA report which generated the headline, “95% of generative AI pilots at companies are failing.”
Plenty have criticized the methodology and conclusions NANDA reaches, but I tend to believe most of the claims in the report provided we keep in mind who was surveyed and understand that “AI pilots” were defined as internally developed applications. Keep this in mind as you review the following two figures:

For all the criticism of the NANDA report, it is a survey of many business leaders. We can treat it as such. So while we might take that 95% figure with a grain of salt, we can trust that business leaders believe the biggest reason their AI pilots are failing is because their employees are unwilling to adopt new tools… While 90% of employees surveyed eagerly use AI tools they procure themselves.
Internal applications struggle, while employee-driven use of ChatGPT and Claude is booming.
Wharton and GBK’s annual AI adoption report appears to counter NANDA with claims that, “AI is becoming deeply integrated into modern work.” 82% of enterprise leaders use Gen AI weekly and 89% “believe Gen AI augments work.”
The Wharton report is an interesting read that details how people are using AI tools throughout their workday. But these are overwhelmingly 3rd party tools:
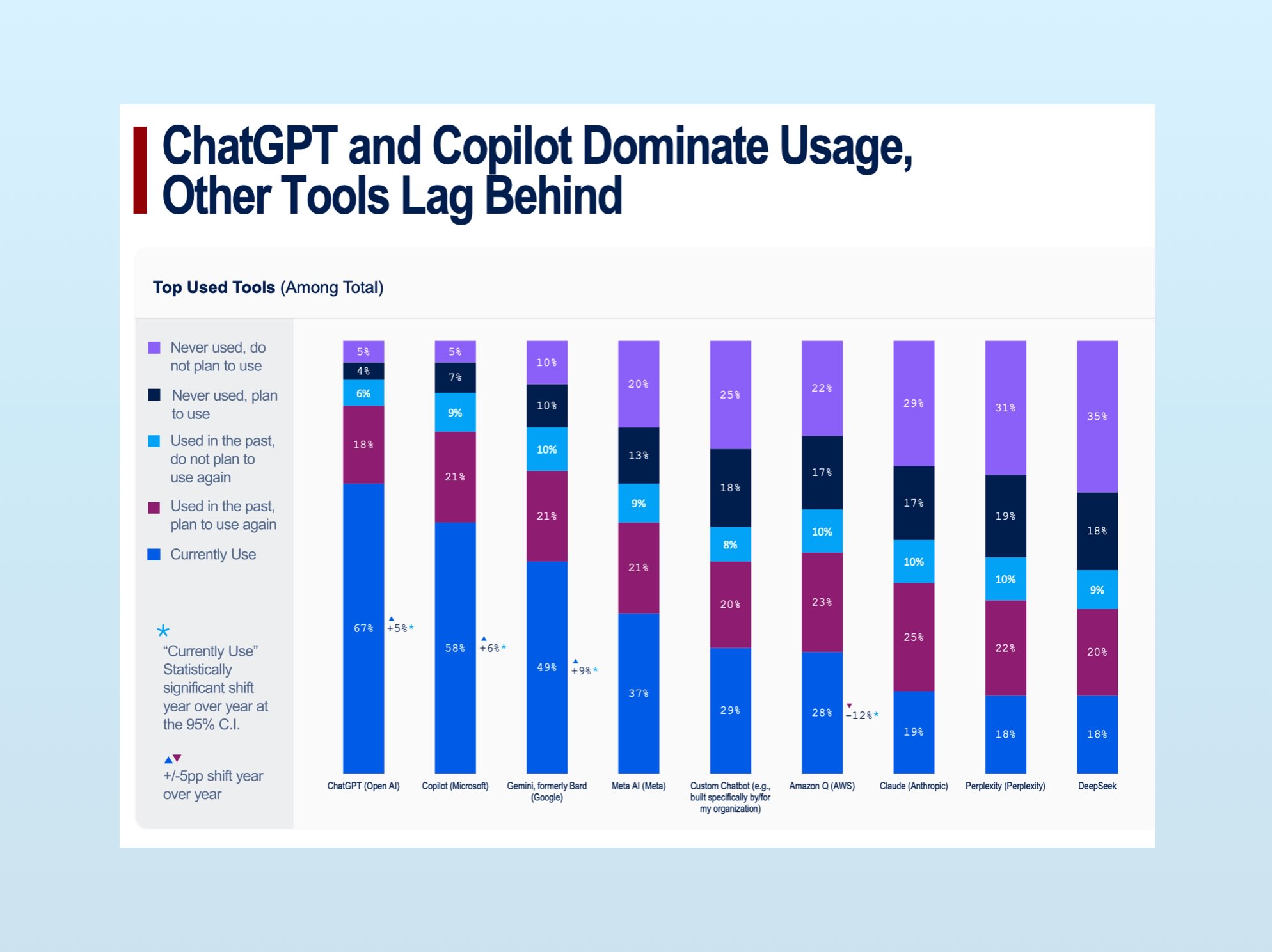
ChatGPT, Copilot, and Gemini dominate usage (Claude ranks surprisingly low, likely a function of Wharton’s respondent base). Custom chatbots see less usage than ChatGPT, and even then: the “by/for” in “built specifically by/for my organization” is doing a lot of work.
10 slides later, the report states (emphasis mine), “Customized Gen AI Solutions May be Coming as Internal R&D Reaches One-Third of Tech Budgets.” The money is being deployed, but customized AI has yet to arrive at scale.
Though they appear to disagree, both reports support a common conclusion: adoption of off-the-shelf tools is growing and valued, but companies struggle to build their own AI tools. Every enterprise AI report I read brings this reality further into focus.
Google Cloud’s “AI Business Trends” report says agents are being widely used… But their definition of “agent” includes ChatGPT, CoPilot, and Claude.
McKinsey’s “State of AI” doesn’t include off-the-shelf tools in their survey, and <10% of respondents report having agents beyond the pilot stage.
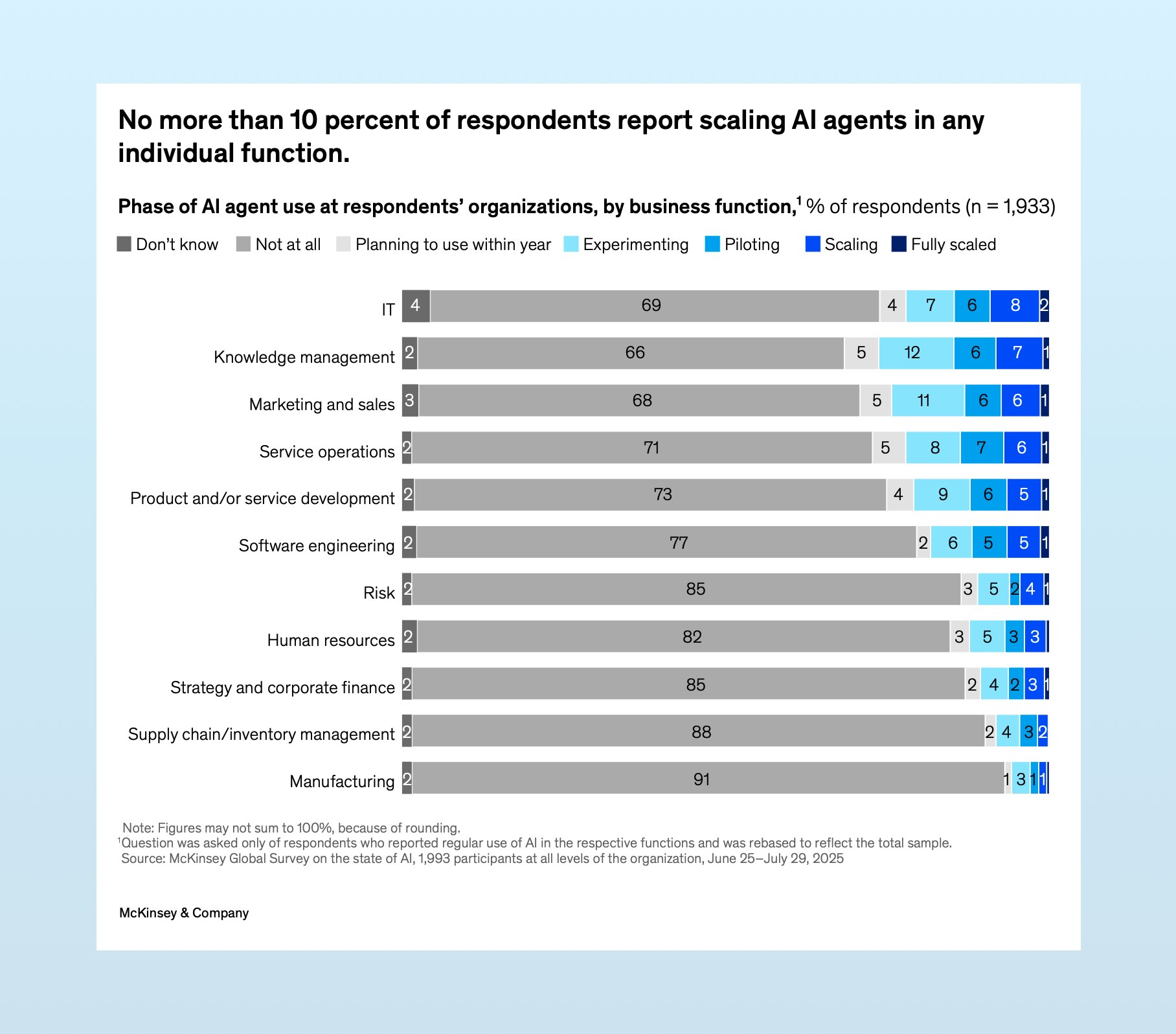
So why is it hard for enterprises to build AI tools? In short: reliability.
“Measuring Agents in Production”, recent research led by Melissa Pan, brings this to life by surveying over 300 teams who actually have agents in production. The headline?
Reliability remains the top development challenge, driven by difficulties in ensuring and evaluating agent correctness.
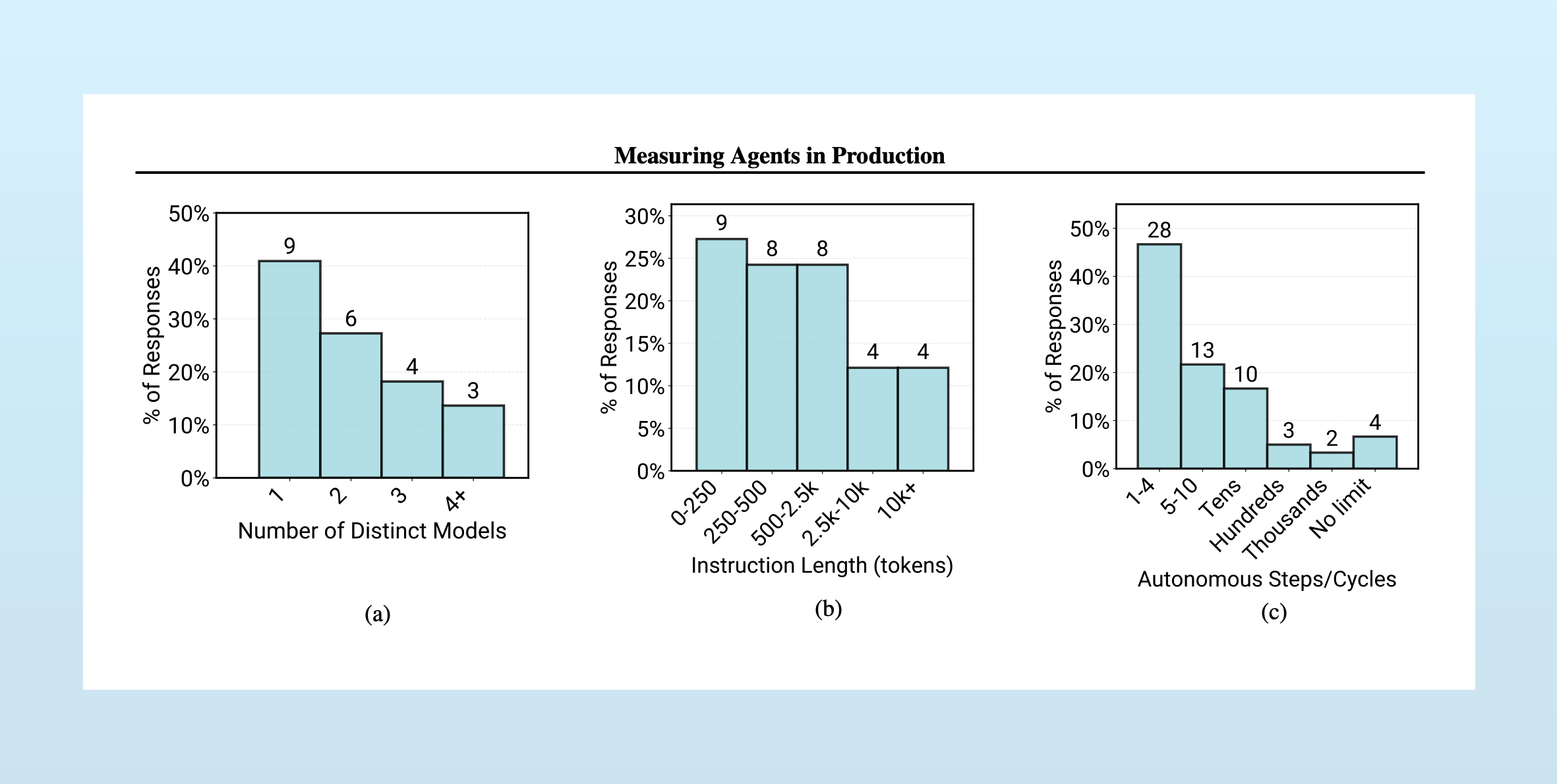
Rather than develop technical innovations to address this issue, developers dial down their agent ambitions and adopt simple methods and workflows. Most use off-the-shelf large models, with no fine-tuning, and hand-tuned prompts. Agents have short run-times, with 68% of agents executing fewer than 10 steps before requiring human intervention. Chatbot UX dominates, because it keeps a human in the loop: 92.5% of in-production agents deliver their output to humans, not to other software or agents. Pan writes, “Organizations deliberately constrain agent autonomy to maintain reliability.”
This aligns with data released by OpenRouter this week, in their “State of AI” report. This report analyzed ~100 trillion tokens passing through OpenRouter, using a projection technique to categorize them by use case.
Prompt and sequence1 lengths are steadily growing for programming use cases, while all other categories remain stagnant:
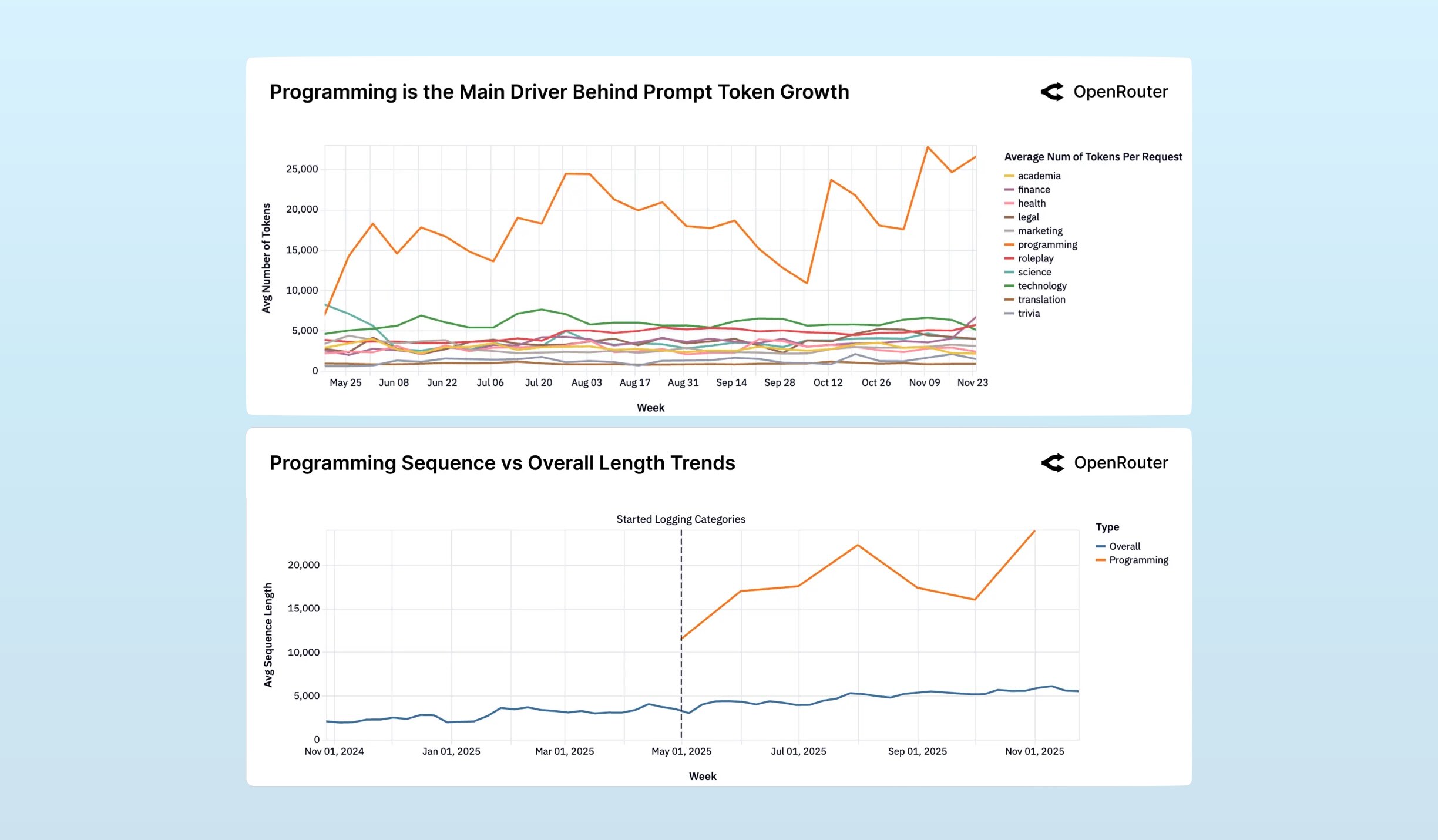
The figures above nicely support Pan’s conclusion that agent builders are keeping their agents simple and short to achieve reliability. Outside of coding agents (whose outlier success is a worth a separate discussion), prompts and agent sequence complexity is stagnant.
And these are the agents that make it into production! MIT NANDA showed that leaders say employee “unwillingness to adopt new tools” is the top barrier facing AI pilots. Pan’s results suggest a more sympathetic explanation: when tools are unreliable, employees don’t adopt them. They’re not stubborn; they’re rational.
In the short term, successful teams will build agents with constrained scope, earn trust, then expand. Delivering on bigger ambitions means building and sharing better tools for reliable AI engineering.
-
“Sequence length is a proxy for task complexity and interaction depth.” ↩