Mistral Small & Human-Centric Benchmarks
I really like small models. They’re fast, cheap, and local – the perfect foundation for fashioning a cog in a compound AI pipeline.
Today, Mistral released Mistral Small 3, “a latency-optimized 24B-parameter model released under the Apache 2.0 license.” At 20GB, Mistral Small 3 runs well on my Mac Studio with 64GB of RAM, though Mistral notes it fits, “in a single RTX 4090 or a 32GB RAM MacBook once quantized.” So far it’s performed very well for me – knocking out code questions, extraction, rephrasing, and other general tasks. It feels on-par with Llama 3.3 70B and Qwen 32B.
But what I really like is how they benchmarked the model. Here’s a screenshot of Mistral Small 3’s Hugging Face page:
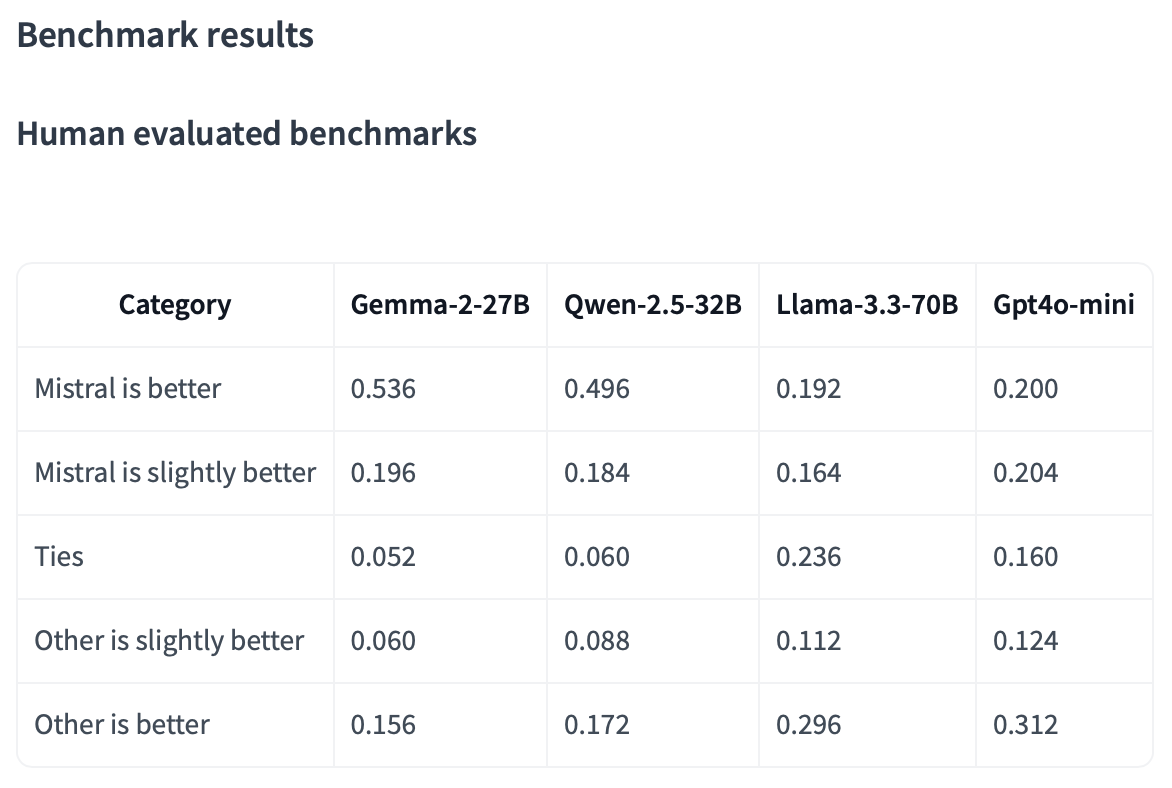
I love this. Rather than highlighting benchmarks irrelevant to their target audience (remember: you really should have your own eval), they’re publishing a quantified table of “vibes.” Below the chart they note:
- We conducted side by side evaluations with an external third-party vendor, on a set of over 1k proprietary coding and generalist prompts.
- Evaluators were tasked with selecting their preferred model response from anonymized generations produced by Mistral Small 3 vs another model.
- We are aware that in some cases the benchmarks on human judgement starkly differ from publicly available benchmarks, but have taken extra caution in verifying a fair evaluation. We are confident that the above benchmarks are valid.
Translated: “Yeah, it’s imperfect, but here’s how people feel using this.” It’s a self-administered Chatbot Arena1 (though they hired a 3rd party to execute it).
I don’t begrudge the big open, standard evals. They push our model development further by putting out crystal-clear challenges for teams to develop against. But it has feels like we’ve been over-fitting to the most popular evals lately. Rough tests like Mistral’s and Chatbot Arena at least attempt to bring some qualitative metrics to the table.
(Personally, I find DeekSeek-R1 to be a prime example of this. It nailed many metrics, leading to the dramatic headlines, but for most tasks I find myself turning to Claude or Llama 3.3, locally.)
Mistral’s vibes preference benchmark here is very welcome. It’s simple and I hope more
-
I’ve noticed Chatbot Arena isn’t cited or discussed as often as it was. In the past, mystery models on their generated waves of speculation and new leaders created waves of headlines. I chalk up it’s decline in popularity to the speed of the field these days – it takes time to establish a good score on Chatbot Arena, which doesn’t fit with the cadence of splashy, spikey launches. ↩