Finding Bathroom Faucets with Embeddings
Using embeddings to navigate impenetrable domains

Embeddings Measure Contextual Similarity
A pretty good, pithy description of neural networks is that they are, “context probability machines.” Provide them with vast quantities of data and they’ll identify patterns, noting where certain data points coincide with others. Once trained, we can provide a neural network with a new bit of data and it will place it within the contextual map it assembled.
Placing a bit of datum into this contextual mapping is called embedding, and is expressed as a vector of numbers. Think of a vector like a latitude and longitude coordinate pair that places a point on a map. But instead of two numbers (lat, lon), a vector might have hundreds of values.
With embeddings we can measure how contextually similar things are to other things; be they words, phrases, blog posts, images, or songs. Embeddings allow us to build “similarity machines” that gauge contextual likeness. Once built, they’re efficient, quick, and extraordinarily powerful.
Which is precisely why I turned to them when shopping for bathroom faucets.
Our family recently started a major home renovation project, an ordeal seemingly designed to generate decision fatigue. There are countless paint swatches, light fixtures, tiles, countertops, and faucets. One plumbing supply website we’ve been browsing contains over 75,000 bathroom faucet options.
Thankfully, we can use the power of embeddings to cut through the noise and navigate this impenetrable domain!
Finding Faucets with Embeddings
What I wanted, which no store website seemed to offer, was a way to find faucets by navigating down a decision tree. Show me a range of faucets, let me select the one I like best, then show me a range of faucets that are similar to the one I selected. Repeat until I find my perfect faucet.
Armed with a collection of nearly 20,000 images of bathroom fixtures and their associated product data, I fired up one of my favorite tools for quickly dealing with embeddings, llm. Written by Simon Willison, llm is a command-line app and Python library for easily interacting with various large language models. It’s a great resource for quickly generating embeddings and comparing them.
Let’s install llm and the model we’ll need:
pip install llm
llm install llm-sentence-transformers
llm install llm-clip
That last line downloads and sets up OpenAI’s CLIP. CLIP is a great model for this use case because it can embed both text and images, and compare across the two.
Assuming you have a directory of images (named “images”), we can generate embeddings for them like so:
llm embed-multi faucets --files images/ '*.jpg' --binary -m clip
All generated embeddings, along with the associated filenames, will be stored in a SQLite database llm maintains. We specify the collection name (“faucets”), for future reference, point llm at a directory of images, specify we’re feeding in binary data (as opposed to text), then specify the model we want to use (CLIP).
Once llm is done generating embeddings, we can use it to compare images, like so:
llm similar faucets -i images/example.jpg --binary
This will embed the provided image (example.jpg) and compare the result to our collection of faucet embeddings. It will then return the top 10 most similar faucets, along with their filenames and similarity scores, as JSON output.
Here are the top 4 faucets recommended when the model is given the large faucet on the left as input:

Pretty good! We’re well on our way to our decision tree tool. We just need to wrap this in a UI.
Building Faucet Finder
For our UI, we’re going to use another of Simon Willison’s tools, datasette. Datasette is a tool for building quick interfaces for SQLite databases (which is how llm stored our embeddings.)
To stand this up, we need to:
- Compile Our Database: We’ll extract our embeddings table from the llm database and load it into a new SQLite database. We then load this database with a separate table containing image and product URLs for each faucet.
- Install Some Plugins: Install the datasette plugins we’ll need: data-template-sql, datasette-faiss, datasette-publish-fly, and datasette-scale-to-zero.
- Design Our Templates: We want two pages for our app. The first serves up a random set of faucet images. Clicking one of these faucets sends you to our second page, which shows you faucets similar to the one you clicked. The first will be our home page, the second will be a “canned query” page that uses datasette-faiss to query our embeddings and accepts a faucet ID as an input parameter. We’ll build both pages using custom templates, overriding datasette’s default styles. For our home page, we’ll execute our query using data-template-sql.
- Deploy Our App: We’ll use Fly.io, datasette-publish-fly and datasette-scale-to-zero.
And voila: Faucet Finder.
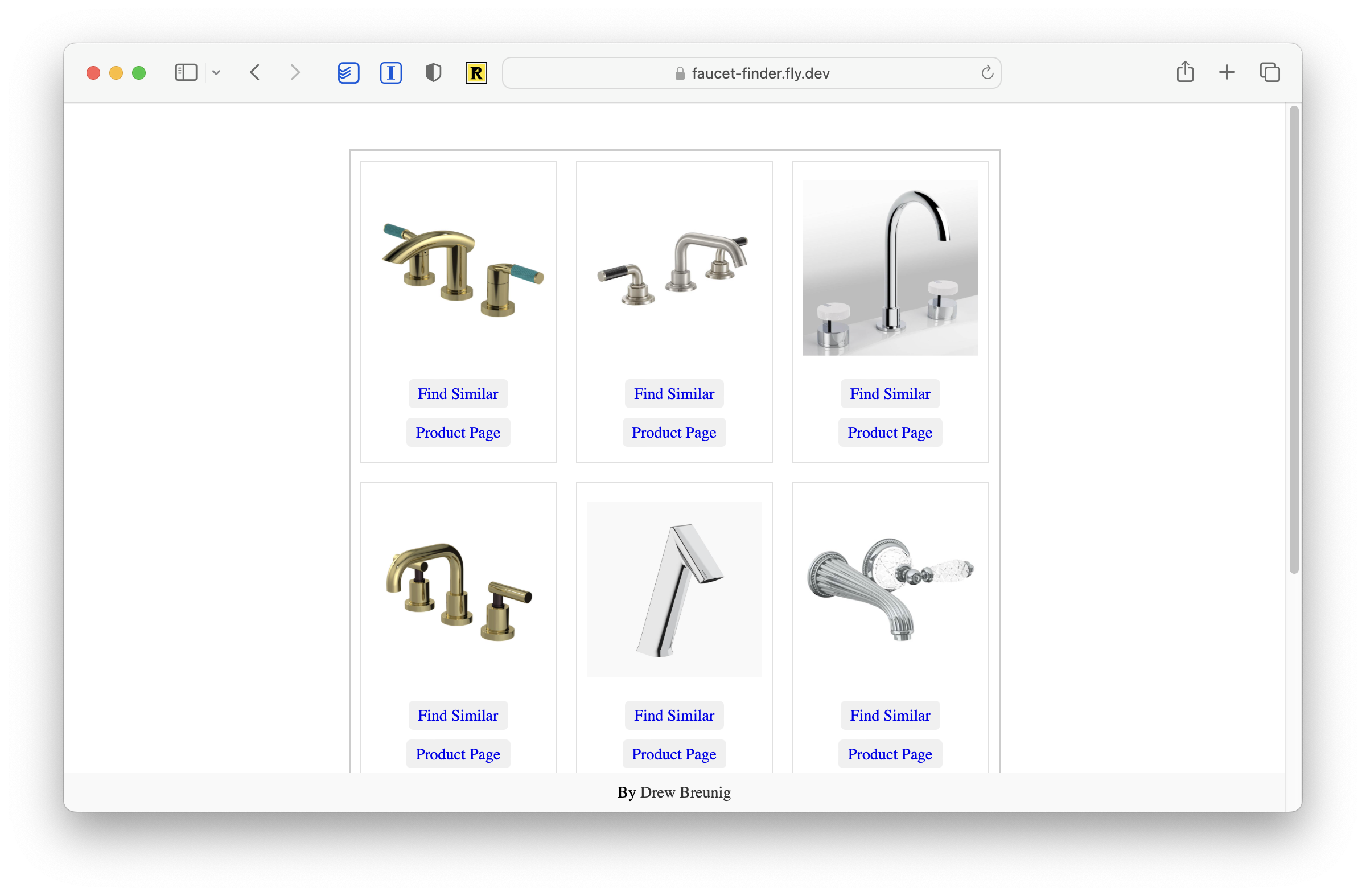
It’s surprisingly effective! Playing with this for 15 minutes or so yielded us several candidates we’re going to evaluate in person.
Bonus: Searching Images with Text
Early we noted that our embedding model, CLIP, can compare both images and text. This yielded a pleasant surprise: we can effectively search for faucets using words and phrases.
We just need to alter our llm command slightly:
llm similar faucets -c "Gawdy"
Which yields…

It’s functional and entertaining. Here are the results for “Bond Villain” and “Nintendo 64”:

Adding this feature to Faucet Finder would take a bit of work, as we’d have to compute the embedding for our text prompt rather than just compare already computed embeddings. If you want to take a crack at it, fork away.
What Could Be Better?
One of my pet peeves when it comes to blog posts and papers dealing with AI is their tendency to only share their best output examples. They don’t show where the model falls down. Attempting to replicate their output rarely yields similar quality results, at least at first.
Which is a shame! The models are usually impressive despite these quirks. There’s just so much noise in the AI space, authors rarely take a warts-and-all approach. You can hardly blame them.
So, in the spirit of transparency, here’s where Faucet Finder falls down:
- Many of the faucet images aren’t contextually consistent, which skews the results. Most are isolated on a white background, but a few pictures are of installed faucets. This can affect the results. If you ask for faucets similar to an image of a faucet on a white background you’ll get a lot of faucets on white backgrounds. If you search with text that describes a context a faucet might be installed in (say, a kitchen or bathroom), you’ll get installed faucets. For example, my search for “a luxury Manhattan apartment in the 1950s” yielded only faucets in situ. If we were building this app for a faucet store or brand, we’d ensure our images were all consistently photographed.
- Not all text prompts yield great results. Some are hilarious, some are fitting, and some are non-sequiturs. By constraining our search area to ~15,000 faucet images we’re dramatically limiting our possible answers. If we were building this general consumption we might limit or prompt users to use certain words and phrases. Or we could include many more images of our faucets in installed environments, which would provide additional context for CLIP to work with.
- Our app could be greatly improved by incorporating some domain knowledge, like finish options, pricing, design lines, and more. In our current app, we are limiting our results to the top result from each faucet brand. This is because brands have many variants of the same faucet. If we didn’t filter, our similarity query would only yield these variants. Adding additional filters or controls using product metadata would provide users with more control and yield better results.
Thankfully, these are small, surmountable problems! There’s no reason even small plumbing stores couldn’t roll out a tool like this on their websites. This took me a few hours to build, most of which was finding the images and waiting for llm to generate the embeddings.
Further: nothing is limiting us to faucets! Given a collection of images and a small dataset, you could build a finder app for any domain. Any store where products are evaluated for their aesthetics could dramatically benefit from such a feature.